01 Nov 2023
Min Read
A Guide to Repartitioning Kafka Topics Using PARTITION BY in DeltaStream
In this blog post we are going to be highlighting why and how to use the PARTITION BY clause in queries in DeltaStream. While we are going to be focusing on repartitioning Kafka data in this post, any data storage layer that uses a key to partition their data can benefit from PARTITION BY.
We will first cover how Kafka data partitioning works and explain why a Kafka user may need to repartition their data. Then, we will show off how simple it is to repartition Kafka data in DeltaStream using a PARTITION BY query.
How Kafka partitions data within a topic
Kafka is a distributed and highly scalable event logging platform. A topic in Kafka is a category of data representing a single log of records. Kafka is able to achieve its scalability by allowing each topic to have 1 or more partitions. When a particular record is produced to a Kafka topic, Kafka determines which partition that record belongs to and the record is persisted to the broker(s) assigned to that partition. With multiple partitions, writes to a Kafka topic can be handled by multiple brokers, given that the records being produced will be assigned to different partitions.
In Kafka, each record has a key payload and a value payload. In order to determine which partition a record should be produced to, Kafka uses the record’s key. Thus, all records with the same key will end up in the same topic partition. Records without a key will be produced to a random partition.
Let’s see how this works with an example. Consider you have a Kafka topic called ‘pageviews’ which is filled with records with the following schema:
The topic has the following records (omitting ts for simplicity):
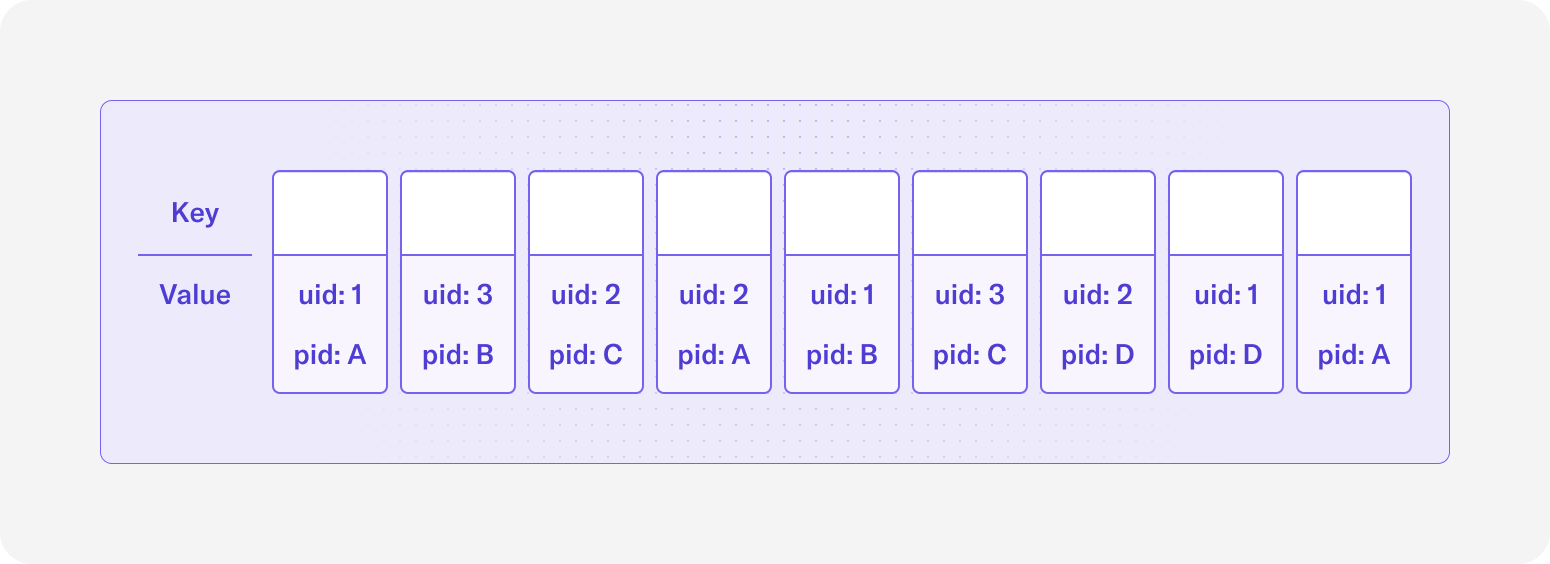
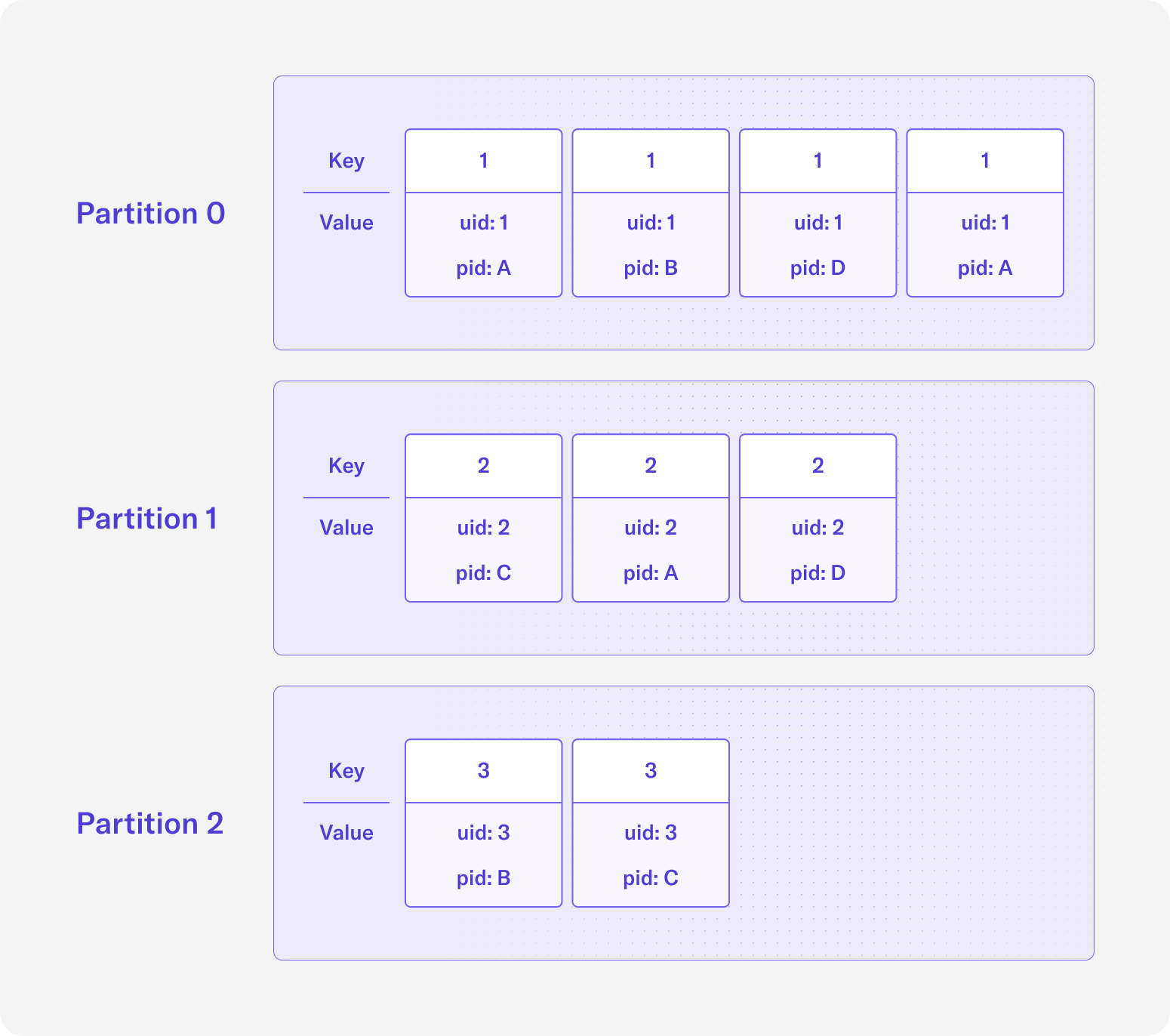
If we partition by the uid field by setting it as the key, then the topic with 3 partitions will look like the following:
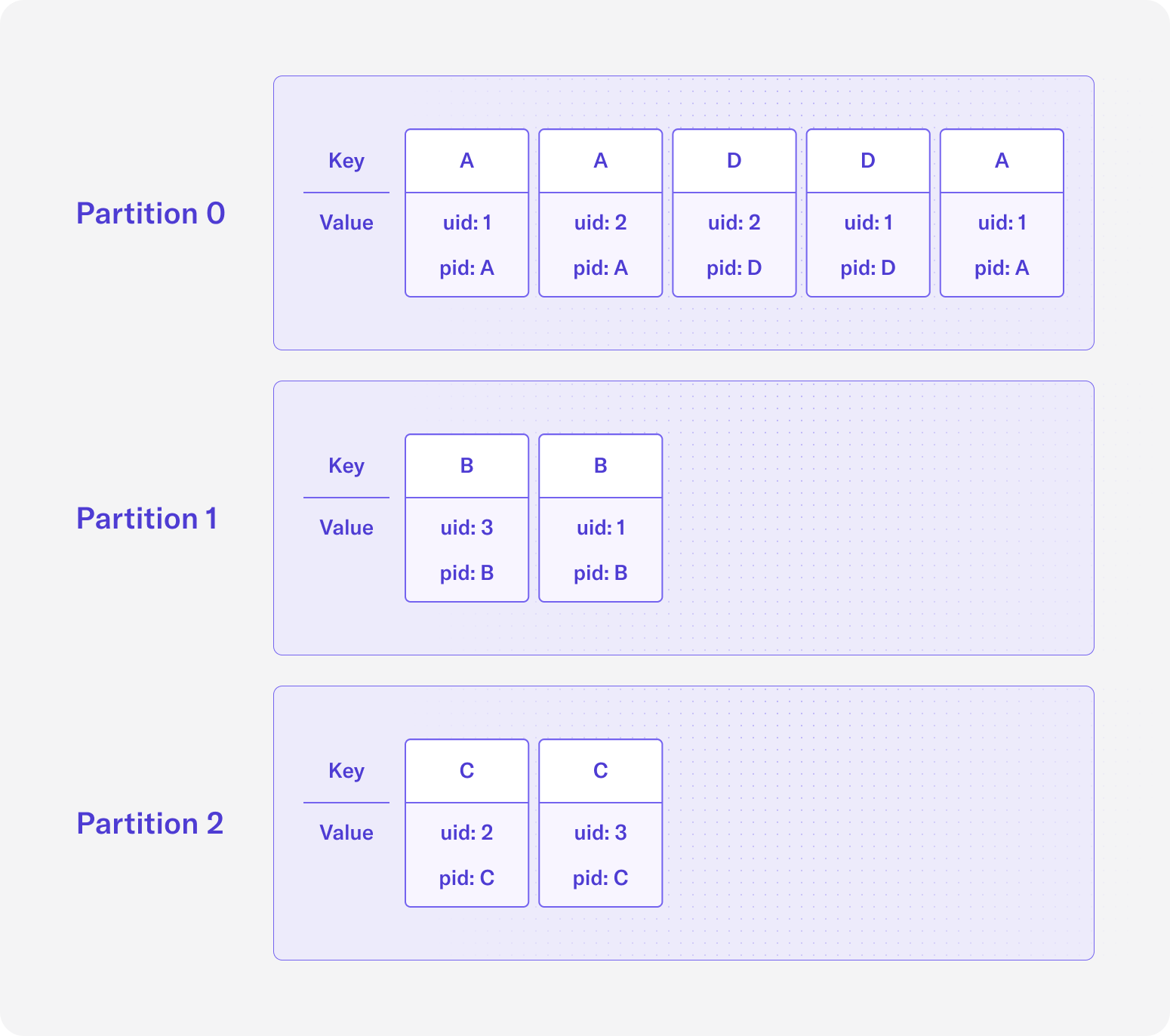
If we partition by the pid field by setting it as the key, then the topic with 3 partitions will look like the following:
Why repartition your Kafka topic
The relationship between partitions and consumers in Kafka for a particular application is such that there can be at most 1 consumer per partition, but a consumer can read from multiple partitions. What this means is if our Kafka topic has 3 partitions and our consumer group has 4 consumers, then one of the consumers will sit idle. In the inverse case, if our Kafka topic has 3 partitions and our consumer group has 2 consumers, then one of the consumers will read from 2 partitions while the other reads from only 1 partition.
In most cases, users will set up their applications that consume from a Kafka topic to have a number of consumers that is a divisor of the number of partitions so that one consumer won’t be overloaded relative to other consumers. However, data can still be distributed unevenly to different partitions if there is a hotkey or poor partitioning strategy, and repartitioning may be necessary in these cases.
To showcase how data skew can be problematic, let’s look again at our pageviews example. Imagine that half of the records have a pid value of A and we partition by the pid field. In a 3 partition topic, ~50% of the records will be sent to one partition while the other two partitions get ~25% of the records. While data skew might hurt performance and reliability for the Kafka topic itself, it can also make it difficult for downstream applications that consume from this topic. With data skew, one or more consumers will be overloaded with a disproportionate amount of data to process. This can have a direct impact on how well downstream applications perform and result in problems such as many very out of order records, exploding application state sizes, and high latencies (see what Apache Flink has implemented to address some of the problems caused by data skew in sources). By repartitioning your Kafka topic and picking a field with more balanced values as the key to partition your data, data skew can be reduced if not eliminated.
Another reason you may want to repartition your Kafka data is to align your data according to its context. In the pageviews example, if we choose the partition key to be the uid field, then all data for a particular user id will be sent to the same partition and thus the same Kafka broker. Similarly, if we choose the partition key to be the pid field, then all data for a particular page id will be sent to the same partition and Kafka broker. If our use case is to perform analysis based on users, then it makes more sense to partition our data using uid rather than pid, and downstream applications will actually process data more efficiently.
Consider we are counting the number of pages a user visits in a certain time window and are partitioning by pid. If the application that aggregates the data has 3 parallel threads to perform the aggregation, each of these threads will be required to read records from all partitions, as the data belonging to a particular uid can exist in many different partitions. If our topic was partitioned by uid instead, then each thread can process data from their own distinct sets of partitions as all data for a particular uid would be available in a single partition. Stream processing systems like Flink and Kafka Streams require some kind of repartition step in their job to handle cases where operator tasks need to process data based on a key and the source Kafka topic is not partitioned by that key. In the case of Flink, the source operators need to map data to the correct aggregation operators over the network. The disk I/O and network involved for stream processing jobs to repartition and shuffle data can become very expensive at scale. By properly partitioning your source data to fit the context, you can avoid this overhead for downstream operations.
PARTITION BY in DeltaStream
Now the question is, how do I repartition or rekey my Kafka topic? In DeltaStream, it’s made simple by PARTITION BY. Given a Kafka topic, you can define a Stream on this topic and write a single PARTITION BY query that rekeys the data and produces the results to a new topic. Let’s see how to repartition a keyless Kafka topic ‘pageviews’.
First, define the ‘pageviews’ Stream on the ‘pageviews’ topic by writing a CREATE STREAM query:
Next, create a long-running CREATE STREAM AS SELECT (CSAS) query to rekey the ‘pageviews’ Stream using uid as the partition key and output the results to a different Stream:
The output Stream, ‘pageviews_keyed’, will be backed by a new topic with the same name. If we PRINT the input ‘pageviews’ topic and the output ‘pageviews_keyed’ topic, we can see the input has no key assigned and the output has the uid value defined as the key.
As you can see, with a single query, you can repartition your Kafka data using DeltaStream in a matter of minutes. This is one of the many ways we remove barriers to make building streaming applications easy.
If you want to learn more about DeltaStream or try it for yourself, you can request a demo or join our free trial.




