13 Jan 2026
Min Read
Bringing Real-Time Context to AgentBricks Agents
Table of contents
- Agents don’t think in batches
- The Databricks approach: incremental, but still micro-batch
- Micro-batch pipelines were never designed for agent-time serving
- DeltaStream takes a fundamentally different path
- Why Flink + ClickHouse beats Structured Streaming + DLTs
- Real-time context is a serving problem, not a compute problem
- DeltaStream inside Databricks: specialization without fragmentation
- Why this matters for agents in practice
- The real conclusion
AI agents have finally arrived in the Databricks ecosystem. With Agent Bricks, Databricks has made it easy to build agents that reason, orchestrate tools, and assist users across analytics and ML workflows. But as teams start putting agents in front of real users, a deeper architectural question quickly emerges:
Where does an agent’s “sense of now” actually come from?
This question exposes a subtle but critical distinction, one that separates systems designed for analytics from systems designed for real-time context. And it’s precisely where DeltaStream becomes essential.
Agents don’t think in batches
Agents behave very differently from dashboards or analysts.
They don’t run long queries. They don’t wait for scheduled refreshes. They ask short, sharp
questions, often repeatedly and concurrently, at inference time:
What’s happening right now?
Why did this change just now?
Who should I worry about at this moment?
To answer these questions well, an agent needs continuously updated state, not periodically
updated tables. This is not just a matter of speed, it’s a matter of architecture.
The Databricks approach: incremental, but still micro-batch
Databricks does allow teams to build incremental context. Using Spark Structured Streaming, developers can process incoming events in micro-batches and feed the results into Delta Live Tables (DLTs). Rolling aggregates, windowed metrics, and continuously updated tables are all possible without recomputing from scratch. For many workloads, this is exactly the right solution.
But there is an important caveat: Structured Streaming is still micro-batch processing, and DLTs are still lakehouse tables.
Even though computation is incremental, it happens at batch boundaries. And even though the tables are “live,” they are served from a storage layer optimized for analytical scans, not real- time interaction.
This distinction matters enormously for agents.
Micro-batch pipelines were never designed for agent-time serving
Structured Streaming pipelines process data in chunks, write results to Delta tables, and rely on the lakehouse query engine to serve results. That engine is designed to optimize throughput, cost, and correctness across large datasets.
Agents, on the other hand, care about:
- Millisecond-level latency
- High query concurrency
- Small, repeated lookups
- Top-N and key-based access patterns
When an agent queries a Delta Live Table, it is still querying files in object storage. Even when the data is fresh, the serving path involves query planning, file access, and scan-oriented execution.
This works, but it does not scale gracefully when agents become interactive, concurrent, and latency-sensitive.
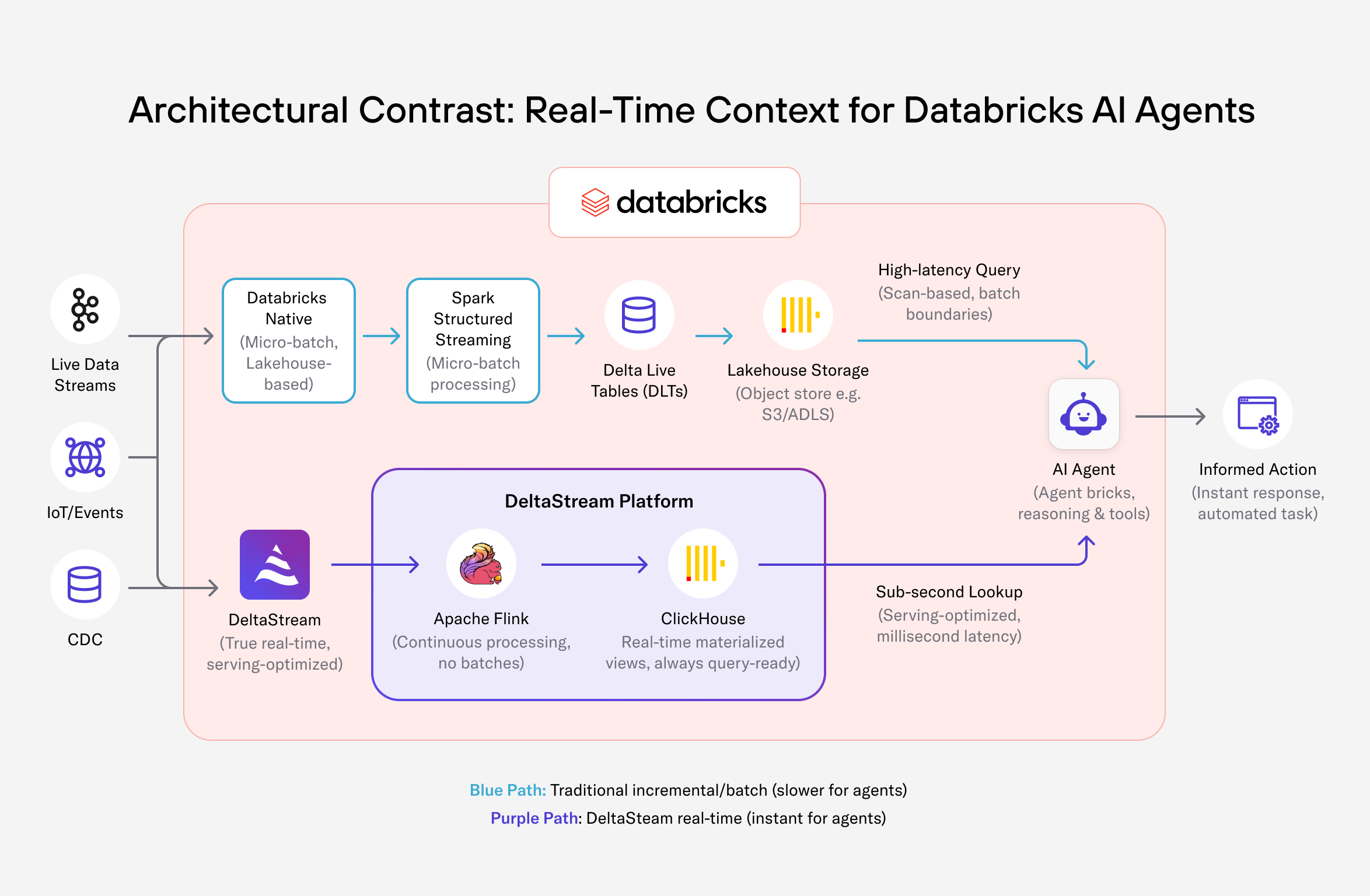
DeltaStream takes a fundamentally different path
DeltaStream starts from a different assumption: real-time context should never be recomputed or scanned at query time. Instead, DeltaStream continuously maintains context as data flows in and serves it from an engine purpose-built for speed. At the heart of this design is the combination of Apache Flink and ClickHouse. Flink processes events one by one, not in micro-batches. There are no batch boundaries, no trigger intervals, and no waiting for the next window to close. State is updated continuously as events arrive. That continuously updated state is then written directly into ClickHouse-backed materialized views, which are always query-ready.
This is the key difference.
Why Flink + ClickHouse beats Structured Streaming + DLTs
The contrast becomes clear when you look at both sides end-to-end.
In the Databricks model, Structured Streaming pipelines compute incrementally, but they still:
- Operate in micro-batches
- Persist results to lakehouse storage
- Serve queries from the same storage layer
In DeltaStream’s model, Flink pipelines:
- Process events continuously, without batching
- Maintain state incrementally in memory
- Feed materialized views that are already optimized for serving
ClickHouse is not a storage layer pretending to be a serving layer. It is a serving engine designed for exactly the kinds of queries agents issue, fast aggregations, filtered lookups, and top-N queries under high concurrency.
This separation of concerns, continuous computation with Flink, real-time serving with ClickHouse, is what makes DeltaStream fundamentally better suited for agent context.
Real-time context is a serving problem, not a compute problem
This is the most important insight.
Databricks can compute incremental context.
DeltaStream can serve it at agent speed.
Agents don’t struggle because computing context is hard. They struggle because serving context fast, repeatedly, and concurrently is hard when your serving layer is a lakehouse.
DeltaStream solves the serving problem by never asking the lakehouse to do what it wasn’t designed to do.
DeltaStream inside Databricks: specialization without fragmentation
Until recently, choosing a Flink + ClickHouse architecture meant adding another platform. That trade-off is gone.
DeltaStream now runs inside the Databricks workspace, bringing true streaming and real-time materialized views directly into the Databricks UI. Teams keep Databricks as their system of record, governance layer, and agent platform, while DeltaStream provides the real-time engine underneath.
Databricks remains the brain.
DeltaStream becomes the nervous system.
Why this matters for agents in practice
Consider a SOC agent answering questions about live security risk.
A Structured Streaming + DLT approach can incrementally compute risk scores, but when an agent asks for the “current highest-risk entity,” it still queries lakehouse tables. As usage grows, latency increases and costs rise.
With DeltaStream, risk scores and correlations are already maintained in ClickHouse. The agent simply reads the answer. No scans. No recomputation. No waiting.
The agent feels instantaneous, not because it’s smarter, but because the context is genuinely real time.
See here for end to end implementation of SOC agent with Agent Bricks and DeltaStream:
https://github.com/deltastreaminc/examples/tree/main/agentbrick
The real conclusion
Databricks gives you the tools to build agents.
DeltaStream gives those agents a real-time sense of the world.
Structured Streaming and Delta Live Tables are excellent for incremental analytics. But when agents need fast, concurrent, inference-time access to continuously updated context, micro-batch pipelines and lakehouse tables become the bottleneck.
By combining:
- Flink’s continuous, non-batch processing
- ClickHouse’s ultra-fast serving
- Databricks’ agent and governance ecosystem
DeltaStream provides what modern agents actually need: real-time context, served at real-time speed.
For Databricks agents, DeltaStream isn’t a convenience.
It’s the missing layer.