10 Feb 2026
Min Read
Why Banking AI Agents Fail, and How Real-Time Context Changes Everything
Table of contents
- The moment support becomes real-time
- Why “just calling the data” breaks in production
- The failure customers feel immediately
- What a banking concierge agent actually needs
- Why real-time context must be built before the agent runs
- A concrete example you can run yourself
- Building the agent with OpenAI Frontier
- Why runtime MCP access alone is not enough
- The difference between demo agents and production agents
- If you’re building enterprise AI agents, this is the line you can’t cross
The first time a banking AI agent gives a wrong answer, the customer doesn’t think, “AI is hard.” They think, “This system doesn’t know what’s going on.”
And they’re right.
Banking support is one of the most obvious use cases for GenAI agents. Customers ask simple questions every day:
- “Where is my transfer?”
- “Why was I charged?”
- “Why does my balance look different?”
- “What’s happening with my dispute?”
These questions sound simple. But they are all questions about live operational reality, not documents, not policies, and not static data. They require the system to know what is true right now, while multiple systems are updating simultaneously.
This is exactly where most AI agents quietly fail.
The moment support becomes real-time
Imagine a customer opens their banking app and asks, “Where is my wire transfer?”
At that exact moment, several things may be happening in parallel:
- The transfer may still be pending, or it may have failed seconds ago.
- The funds may already be moving back to the available balance.
- A notification may have just been sent.
- A temporary hold may have been placed or released.
- The ledger may not yet reflect the final state.
The customer isn’t asking for a policy explanation. They’re asking for the current truth.
Most agent architectures were never designed for this.
Why “just calling the data” breaks in production
The common approach looks reasonable at first. When a customer asks a question, the agent pulls data from the ledger service, the payments system, the transfers API, the disputes service, and the notifications log. The agent stitches those responses together into a prompt and asks the LLM to reason.
In demos, this often works. In production, it breaks.
The problem is subtle but fatal: there is no single “now.”
Each backend system updates independently. Each API call returns data from a slightly different point in time. Under load, those differences grow. By the time the agent assembles its prompt, it is reasoning over a state that never actually existed.
The LLM doesn’t know that. It fills in the gaps and produces a confident answer.
That’s how you get answers that are linguistically correct and operationally wrong.
The failure customers feel immediately
Here’s what that failure looks like in practice.
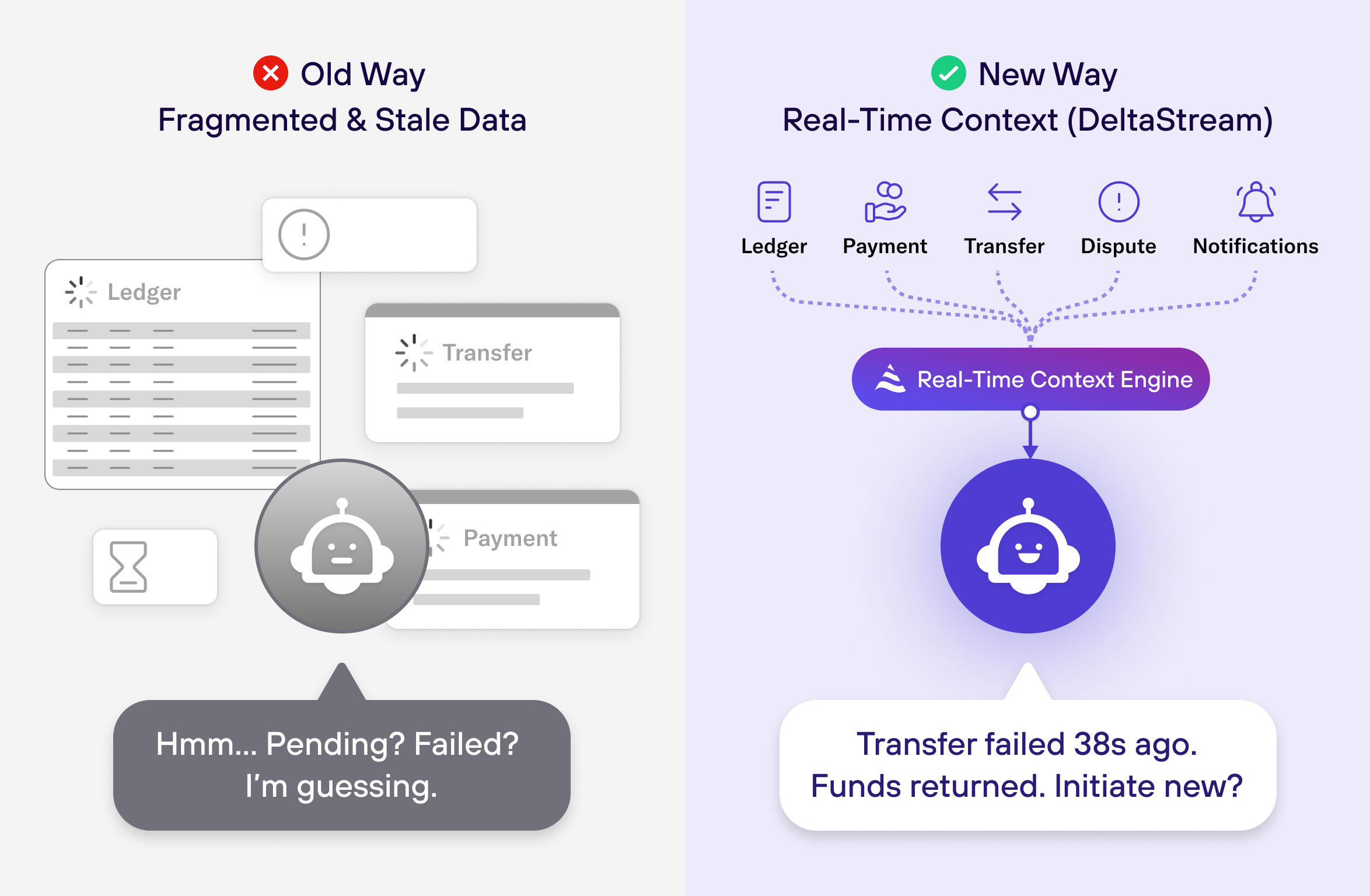
Customer: “Where is my wire transfer?”
Agent: “Your wire transfer is currently pending and should complete soon.”
Customer: “That’s strange, I just got a notification saying it failed.”
Agent: “Let me check again.”
At that moment, the conversation is already lost. The customer no longer trusts the system.
Escalation is inevitable. The AI agent becomes a liability instead of a solution.
Now contrast that with an agent that has access to real-time context.
Customer: “Where is my wire transfer?”
Agent: “I can see your transfer was updated 38 seconds ago. It failed and was returned due to
a beneficiary rejection. The funds are already moving back to your available balance. Would you
like help initiating a new transfer?”
Same customer. Same model.
The difference is not intelligence, it’s context.
What a banking concierge agent actually needs
To answer support questions correctly, an agent needs a continuously updated view of the customer’s current state. Not partial data. Not best-effort snapshots. A coherent, consistent picture of reality that includes balances, authorizations, transfers, holds, disputes, and even what the customer was already told moments ago.
This context changes minute by minute, sometimes second by second. Trying to assemble it on demand guarantees inconsistency and latency. The agent ends up acting like a distributed query engine instead of a decision and communication layer.
The agent’s job should be to reason, explain, and act, after the truth is established.
Why real-time context must be built before the agent runs
This is where the architecture must change.
Instead of asking agents to pull raw data and figure things out at runtime, DeltaStream continuously computes the customer’s live operational state as data flows in. Ledger updates, authorization events, transfer lifecycle changes, holds, disputes, and notifications are joined and enriched in real time into materialized views that always reflect current truth.
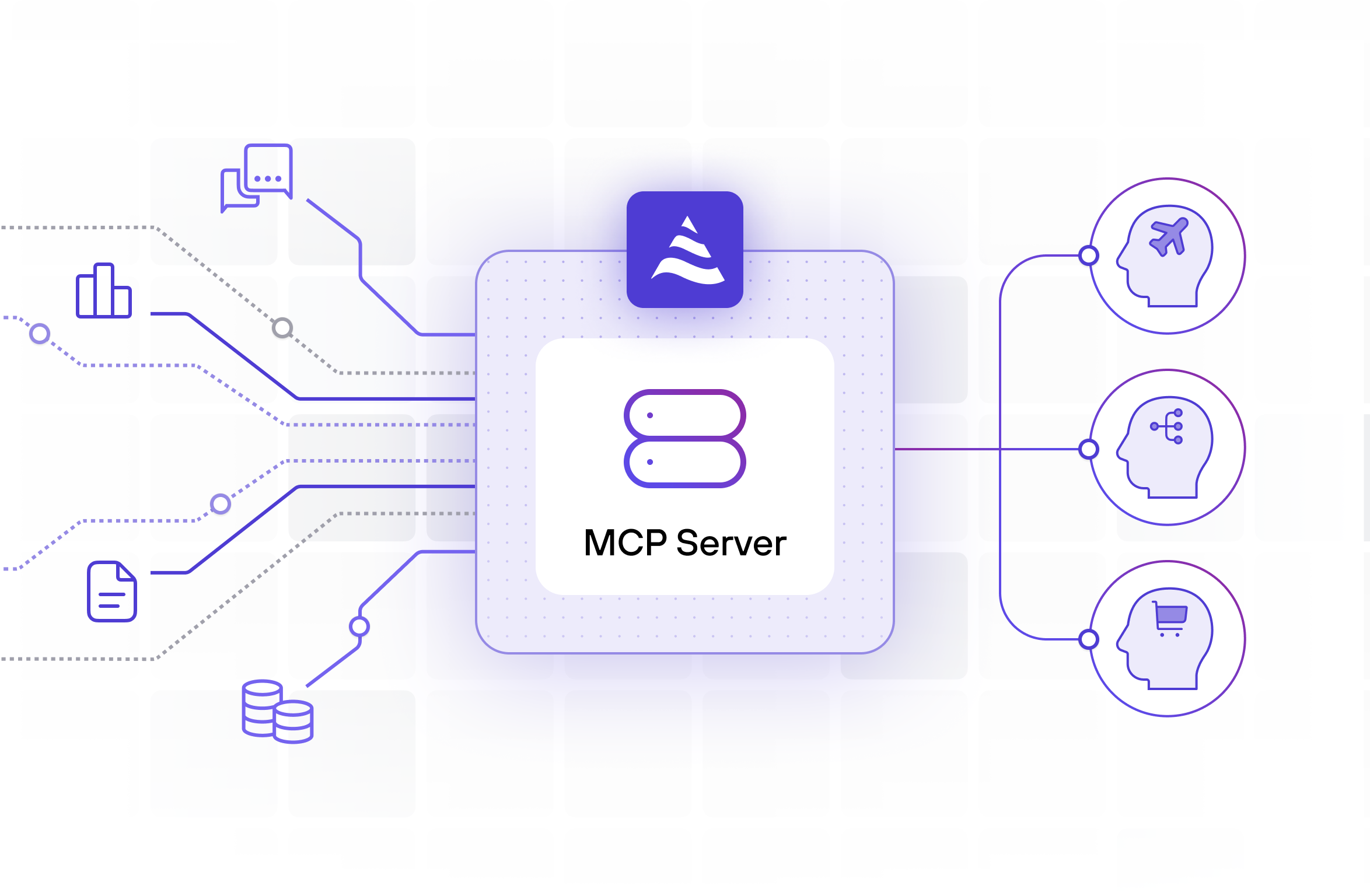
When an agent needs context, it doesn’t orchestrate six backend calls. It makes a single request through DeltaStream’s built-in MCP server and receives a ready-to-use, up-to-the- moment snapshot of the customer’s situation.
At that point, the LLM can do what it’s good at: explain what’s happening, choose the right next step, and communicate clearly and confidently.
A concrete example you can run yourself
To make this tangible, we built a full end-to-end example of a Banking Customer Support / Concierge Agent.
The example includes a small data generator that produces realistic banking events, ledger updates, authorization events, transfer status changes, holds, disputes, and customer notifications, into Kafka. DeltaStream continuously processes these streams and materializes the real-time contexts the agent relies on, including a unified “support context” and supporting views like recent activity summaries and “latest per customer” indicators.
All of these contexts are exposed to the agent through DeltaStream’s MCP server, so the agent can retrieve live context in a single call instead of stitching data together at runtime.
The full implementation, including the data generator and all DeltaStream statements, is available in the DeltaStream examples GitHub repository. You can run it, modify it, and adapt it to your own systems ( https://github.com/deltastreaminc/examples/tree/main/BankingCustomerSupport ).
Building the agent with OpenAI Frontier
On the agent side, OpenAI’s Frontier platform makes this pattern straightforward.
You define a support agent that can call tools, and you register DeltaStream’s MCP endpoint as a tool provider. When a customer asks a question, the agent first calls MCP to fetch the real-time support context. Frontier passes that structured context to the model, and the LLM generates a response grounded in the latest state.
The model is never asked to reconstruct reality. It’s asked to communicate reality.
This separation, DeltaStream owning truth, the agent owning reasoning, is what makes the system reliable.
Why runtime MCP access alone is not enough
Some teams assume exposing raw systems through MCP solves the problem. It doesn’t. It simply moves the complexity closer to the agent.
You still pay the latency cost of multiple calls. You still get inconsistent timestamps. You still rebuild joins and logic per prompt. You still end up with different agents seeing slightly different versions of truth. Governance and auditability become harder, not easier.
DeltaStream flips the model. Context is built once, continuously, in a governed and observable way. Every agent sees the same truth. Every response is explainable. Every decision is grounded in reality.
The difference between demo agents and production agents
The difference isn’t the model.
It isn’t the prompt.
It isn’t even the agent framework.
It’s whether the agent reasons over fresh, shared, real-time context or improvises over stale
fragments of data.
In banking, and in any enterprise environment where the world changes while users are
interacting, real-time context is not an optimization. It is the foundation.
If you’re building enterprise AI agents, this is the line you can’t cross
If your agents are expected to answer questions, trigger actions, or represent your business in live workflows, they must know what’s true now. Not five minutes ago. Not eventually. Not after another retry.
DeltaStream exists to make that possible.
It gives your agents a real-time, trustworthy view of the world, so they can stop guessing and start acting with confidence.
If you’re building enterprise AI agents, make real-time context your default. Make DeltaStream your Real-Time Context Engine.
This blog was written by the author with assistance from AI to help with outlining, drafting, or editing.