06 Nov 2024
4 Min Read
Open Sourcing our Snowflake Connector for Apache Flink
November 2024 Updates:
- Support wider range of Apache Flink environments, including Managed Service for Apache Flink and BigQuery Engine for Apache Flink, with Java 11 and 17 support.
- Fixes an issue affecting compatibility with Google Cloud Projects
- Upgraded to Apache Flink 1.19.
- See full release details
At DeltaStream our mission is to bring a serverless and unified view of all streams to make stream processing possible for any product use case. By using Apache Flink as our underlying processing engine, we can leverage its rich connector ecosystem to connect to many different data systems, breaking down the barriers of siloed data. As we mentioned in our Building Upon Apache Flink for Better Stream Processing article, using Apache Flink is more than using robust software with a good track record at DeltaStream. Using Flink has allowed us to iterate faster on improvements or issues that arise from solving the latest and greatest data engineering challenges. However, one connector that was missing until today was the Snowflake connector.
Today, in our efforts to make solving data challenges possible, we are open sourcing our Apache Flink sink connector built for writing data to Snowflake. This connector has already provided DeltaStream with native integration between other sources of data and Snowflake. This also aligns well with our vision of providing a unified view over all data, and we want to open this project up for public use and contribution so that others in the Flink community can benefit from this connector as well.
The open-source repository will be open for contributions, suggestions, or discussions. In this article, we touch on some of the highlights of this new Flink connector.
Utilizing the Snowflake Sink
The Flink connector uses the latest Flink Sink<InputT> and SinkWriter<InputT> interfaces to build a Snowflake sink connector and write data to a configurable Snowflake table, respectively:
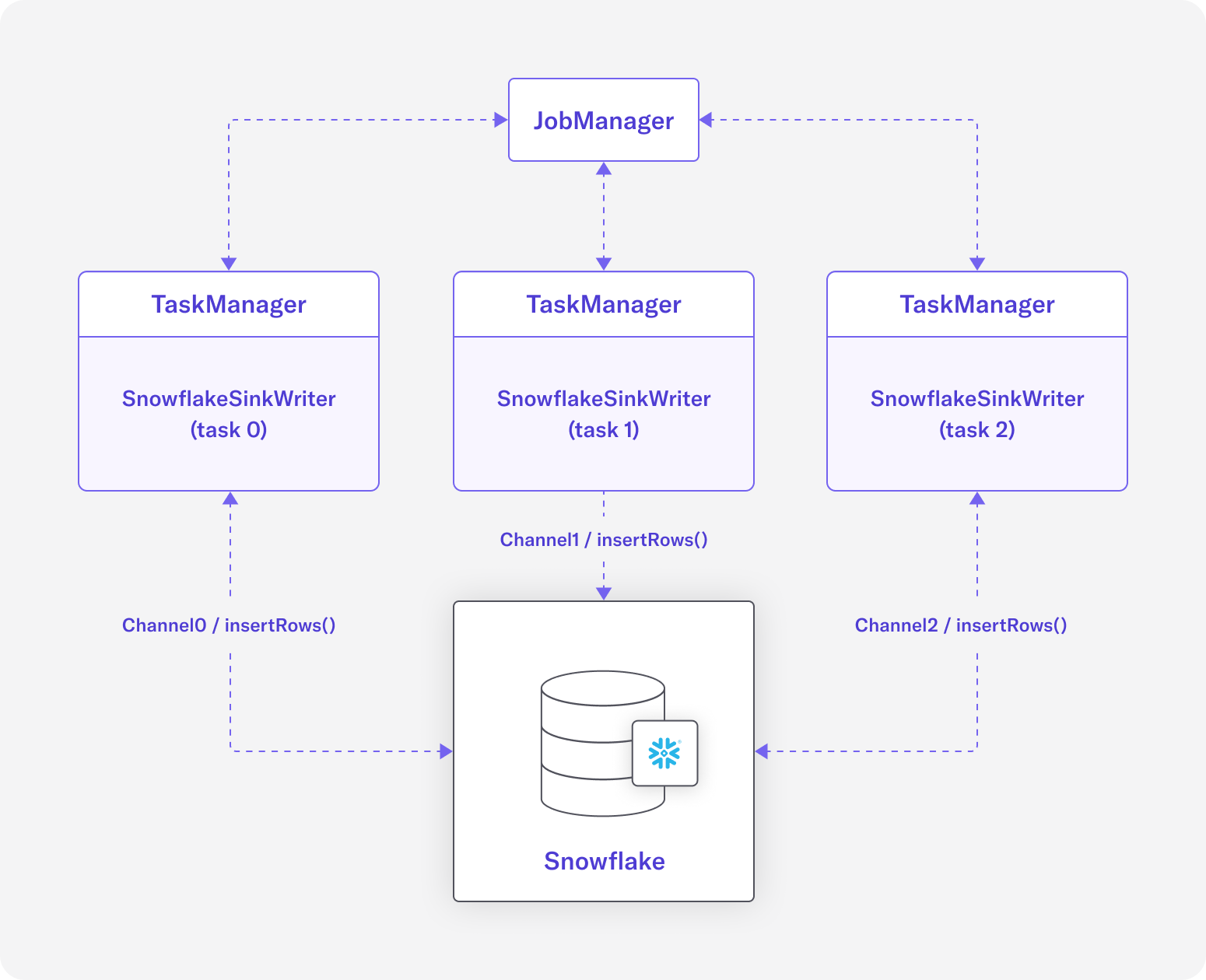
Diagram 1: Each SnowflakeSinkWriter inserts rows into Snowflake table using their own dedicated ingest channel
The Snowflake sink connector can be configured with a parallelism of more than 1, where each task relies on the order of data it receives from its upstream operator. For example, the following shows how data can be written with parallelism of 3:
Diagram 1 shows the flow of data between TaskManager(s) and the destination Snowflake table. The diagram is heavily simplified to focus on the concrete SnowflakeSinkWriter<InputT>, and it shows that each sink task connects to its Snowflake table using a dedicated SnowflakeStreamingIngestChannel from Snowpipe Streaming APIs.
The SnowflakeSink<InputT> is also shipped with a generic SnowflakeRowSerializationSchema<T> interface that allows each implementation of the sink to provide its own concrete serialization to a Snowflake row of Map<String, Object> based on a given use case.
Write Records At Least Once
The first version of the Snowflake sink can write data into Snowflake tables with the delivery guarantee of NONE or AT_LEAST_ONCE, using AT_LEAST_ONCE by default. Supporting EXACTLY_ONCE semantics is a goal for a future version of this connector.
The sink writes data into its destination table after buffering records for a fixed time interval. This buffering time interval is also bounded by Flink’s checkpointing interval, which is configured as part of the StreamExecutionEnvironment. In other words, if Flink’s checkpointing interval and buffering time are configured to be different values, then records are flushed as fast as the shorter interval:
In this example, the checkpointing interval is set to 100 milliseconds, and the buffering interval is configured as 1 second. This tells the Flink job to flush the records at least every 100 milliseconds, i.e., on every checkpoint.
Read more about Snowpipe Streaming best practices in the Snowflake documentation.
The Flink Community, to Infinity and Beyond
We are very excited about the opportunity to contribute our Snowflake connector to the Flink community. We’re hoping this connector will add more value to the rich connector ecosystem of Flink that’s powering many data application use cases.If you want to check out the connector for yourself, head over to the GitHub repository. Or if you want to learn more about DeltaStream’s integration with Snowflake, read our Snowflake integration blog.