10 May 2023
8 Min Read
Why Apache Flink is the Industry Gold Standard
What is Apache Flink?
Apache Flink is a distributed data processing engine that is used for both batch processing and stream processing. Although Flink supports both batch and streaming processing modes, it is first and foremost a stream processing engine used for real-time computing. By processing data on the fly as a stream, Flink and other stream processing engines are able to achieve extremely low latencies. Flink in particular is a highly scalable system, capable of ingesting high throughput data to perform stateful stream processing jobs while also guaranteeing exactly-once processing and fault tolerance. Initially released in 2011, Flink has continuously been updated and grown into one of the largest open source projects. Large and reputable companies such as Alibaba, Amazon, Capital One, Uber, Lyft, Yelp, and others have relied on Flink to provide real-time data processing to their organizations.
Flink’s Place in the Data Industry
Before stream processing, companies relied on batch jobs to fulfill their big data needs, where jobs would only perform computations on a finite set of data. However, many use cases don’t naturally fit a batch model. Consider fraud detection for example, where a bank may want to act if anomalous credit card behavior is detected. In the batch world, the bank would need to collect credit card transactions over a period of time, then run a batch job over that data to determine if a transaction is potentially a fraudulent one. Since the batch job is run after the data collection, by the time the batch job finishes, it might not be until a few hours that a transaction is marked as fraudulent, depending on how frequently the job is being scheduled. In the streaming world, transactions can be processed in real time and the latency for action will be less. Being able to freeze credit card accounts in real-time can save time and money for the bank. You can read more about the distinction of streaming vs batch in our other blog post.
Without Apache Flink or other stream processing engines, you could still write code to read from a streaming message broker (e.g. Kafka, Kinesis, RabbitMQ) and do stream processing from scratch. However, with this approach you would miss out on many of the features that modern stream processing engines give you out of the box, such as fault tolerance, the ability to perform stateful queries, and API’s that vastly simplify processing logic. There are many stream processing frameworks in addition to Apache Flink such as Kafka Streams, ksqlDB, Apache Spark (Spark streaming), Apache Storm, Apache Samza, and dozens of others. Each have their own pros and cons and comparing them could easily become its own blog post, but Apache Flink has become an industry favorite because of these key features:
- Flink’s design is truly based on processing streams instead of relying on micro-batching
- Flink’s checkpointing system and exactly-once guarantees
- Flink’s ability to handle large throughputs of data from many different types of data sources at a low latency
- Flink’s SQL API that leverages Apache Calcite allows users to define their Flink jobs using SQL, making it easier to build applications
How Apache Flink works
Flink is designed to be a highly scalable distributed system, capable of being deployed with most common setups, that can perform stateful computations at in-memory speed. To get a high level understanding about Flink’s design, we can look further into the Flink ecosystem and execution model.
The Flink ecosystem can be broken down into 4 layers:
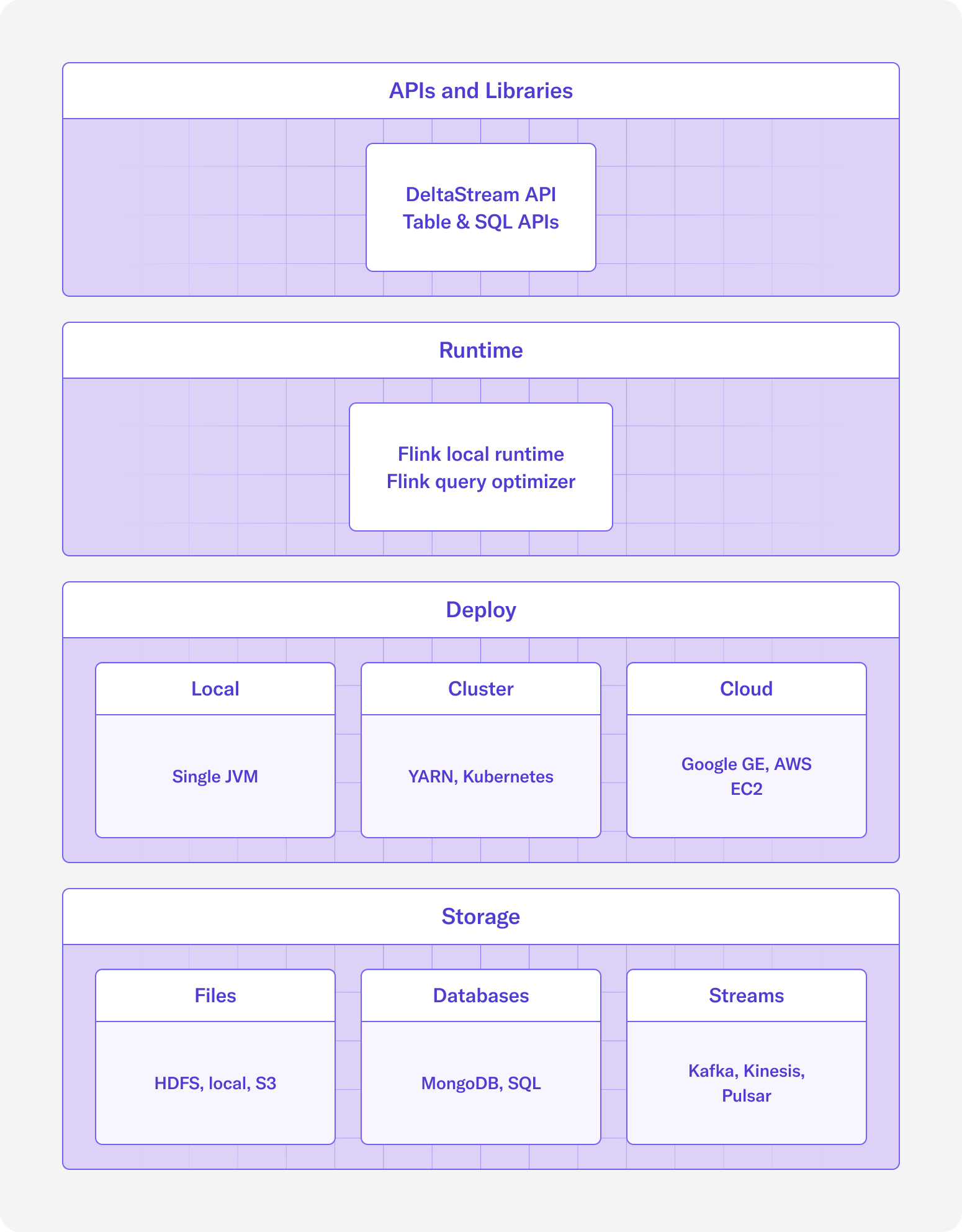
- Storage: Flink doesn’t have its own storage layer and instead relies on a number of connectors to connect to data. These include but are not limited to HDFS, AWS S3, Apache Kafka, AWS Kinesis, and SQL databases. You can similarly use managed products such as Amazon MSK, Confluent Cloud, and Redpanda among others.
- Deploy: Flink is a distributed system and integrates seamlessly with resource managers like YARN and Kubernetes, but it can also be deployed in standalone mode or in a single JVM.
- Runtime: Flink’s runtime layer is where the data processing happens. Applications can be split into tasks that are parallelizable and thus highly scalable across many cluster nodes. With Flink’s incremental and asynchronous checkpointing algorithm, Flink is also able to provide fault tolerance for applications with large state and provide exactly-once processing guarantees while minimizing the effect on processing latency.
- APIs and Libraries: The APIs and libraries layer are provided to make it easy to work with Flink’s runtime. The DataStream API can be used to declare stream processing jobs and offers operations such as windowing, updating state, and transformations. The Table and SQL APIs can be used for batch processing or stream processing. The SQL API allows users to write SQL queries to define their Flink jobs and the Table API allows users to call functions on their data based on Table schemas used to define them.
In the execution architecture, there is a client and the Flink cluster. Two kinds of nodes make up the Flink cluster – the Job manager and the Task manager. There is always a Job manager and any number of Task managers.
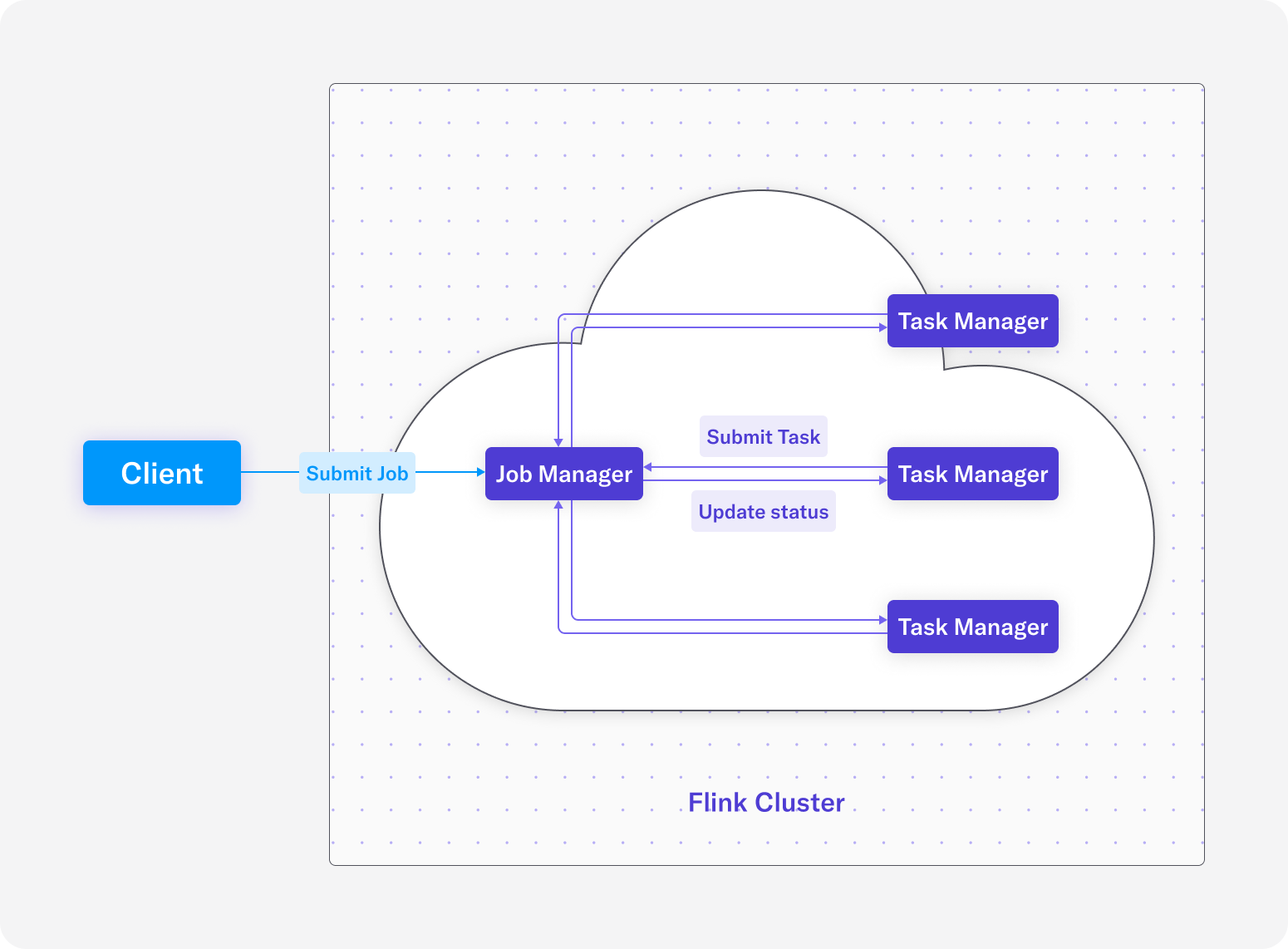
- Client: Responsible for generating the Flink job graph and submitting it to the Job manager.
- Job manager: Receives the job graph from the Client then schedules and oversees the execution of the job’s tasks on the Task managers.
- Task manager: Responsible for executing all the tasks it was assigned from the Job manager and report updates on its status back to the Job manager.
In Figure 1, you’ll notice that storage and deployment are somewhat detached from the Flink runtime and APIs. The benefit of designing Flink this way is that Flink can be deployed in any number of ways and connect to any number of storage systems, making it a good fit for almost any tech stack. In Figure 2, you’ll notice that there can be multiple Task managers and they can be scaled horizontally, making it easy to add resources to run jobs at scale.
What makes Apache Flink the data industry gold standard
Apache Flink has become the most popular real-time computing engine and the industry gold standard for many reasons, but its ability to process large volumes of real-time data with low latency is its main draw. Other features include the following:
- Stateful processing: Flink is a stateful stream processor, allowing for transformations such as aggregations and joins of continuous data streams.
- Scalability: Flink can scale up to thousands of Task manager nodes to handle virtually any workload without sacrificing latency.
- Fault tolerance: Flink’s state of the art checkpointing system and distributed runtime makes it both fault tolerant and highly available. Checkpoints are used to save the application state, so when your application inevitably encounters a failure, the application can be resumed from the latest checkpoint. For applications that use transactional sinks, exactly-once end to end processing can be achieved. Also, since Flink is compatible with most resource management systems like YARN and Kubernetes, when nodes crash they will automatically be restarted. Flink also has high availability setup options based on Apache Zookeeper to help prevent failure states as well.
- Time mechanisms: Flink has a concept called “watermarks” for working with event time which represents the application’s progress with regard to time. Different watermark strategies can be applied to allow users to configure how they want to handle out of order or late data. Watermarks are important for the system to understand when it is safe to close windows and emit results for stateful operations.
- Connector ecosystem: Since Flink uses external systems for storage, Flink has a rich ecosystem of connectors. Wherever your data is, Flink likely already has a library to connect to it. Popular existing connectors include connectors for Apache Kafka, AWS Kinesis, Apache Pulsar, JDBC connector for databases, Elasticsearch, and Apache Cassandra. If a connector you need doesn’t exist, Flink provides APIs to help you create a new connector.
- Unified batch and streaming: Flink is both a batch and stream processor, making it an ideal candidate for applications that need both streaming and batch processing. With Flink, you can use the same application logic for both cases reducing the headache of managing two different technologies.
- Large open source community: In 2022, Flink had over 1,600 contributions and the Github project currently has over 21 thousand stars. To put this in perspective, Apache Kafka currently has 24,800 stars and Apache Hadoop currently has 13,500 thousand stars. Having a large and active open source community is extremely valuable for fixing bugs and staying up to date with the latest tech requirements.
Conclusion
In this blog post, we’ve introduced Apache Flink at a high level and highlighted some of its features. While we would suggest those who are interested in adding stream processing to their organizations to take a survey of the different stream processing frameworks available, we’re also confident that Flink would be a top choice for any use case. At DeltaStream, although we are detached from using any particular compute engine, we have chosen to use Flink for the reasons explained above. DeltaStream is a unified, serverless stream processing platform that takes the pain out of managing your streaming stores and launching stream processing queries. If you’re interested in learning more get a free trial of DeltaStream.