19 Oct 2023
Min Read
Capturing Data Changes in Real-Time
Change Data Capture (CDC) is a data integration technique to identify changes in a data source in real-time and capture them in downstream systems such as databases or data lakes to ensure consumers always have access to the most up-to-date data. Changes in the source data are continuously recorded as they occur. These changes are then made available for different purposes such as replication, synchronization, migration or transformation to other systems. CDC is well-suited for relational databases, which are often a critical part of enterprise systems. CDC captures data changes at the operation level and provides fine-grained control over data changes. This is useful for tracking historical data and handling complex data synchronization scenarios. Moreover, CDC often maintains transactional context in the source, ensuring that changes are delivered in a consistent order, reflecting the order of transactions in the source system. CDC pipelines are designed for high reliability and data consistency and therefore they include built-in mechanisms for error handling, retries for failed operations, and ensure data integrity.
What does a Change Data Capture pipeline look like?
A CDC pipeline typically consists of multiple components and stages designed to efficiently transfer data changes from a source system to a target system. The “source system” represents the original data where changes must be identified and captured. Within the pipeline, a “CDC capture agent” plays a pivotal role by continuously monitoring data changes in the source, capturing inserts, updates or deletions. Every change event is recorded and subsequently, in accordance with the chosen CDC delivery method, this ‘change log’ is published to the ‘target system’ where the captured changes are stored in a format optimized for subsequent processing.
Change Data Capture pipelines in DeltaStream
Just like you can use DeltaStream to process streaming data from sources like Kafka, you can now use DeltaStream to efficiently create pipelines to propagate CDC logs from PostgreSQL to a sink. Such a pipeline tracks data changes (INSERT, DELETE, UPDATE), at the row level in a table defined in a PostgreSQL database and pushes them into a downstream sink such as a Kafka topic or downstream analytics database such as Databricks.
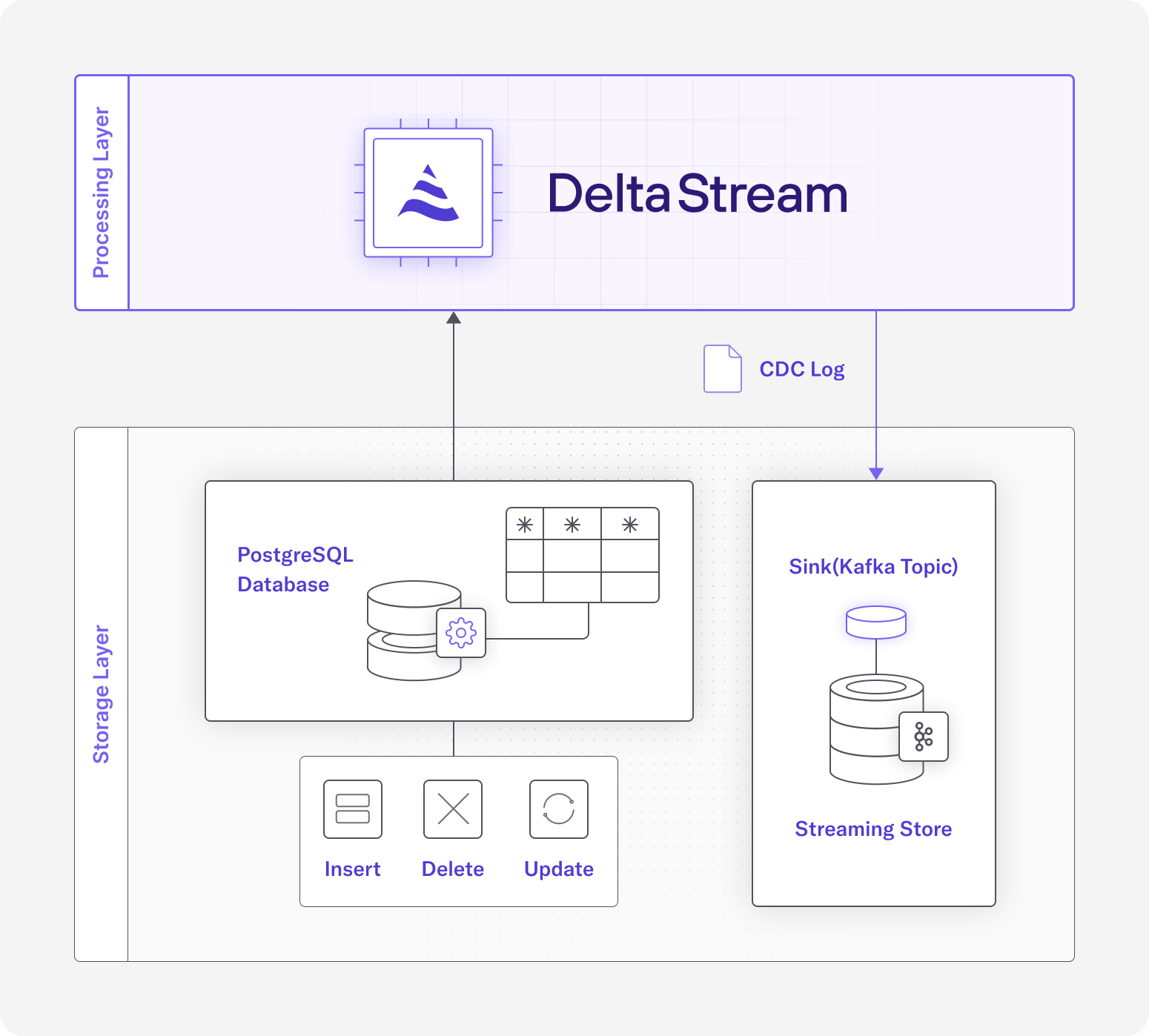
Here, we cover an example to show how you can define and run such a pipeline. Assume you have a table, named pageviews in a PostgreSQL database called visits. Each row in pageviews has 3 columns: viewtime, userid and pageid and shows when a specific user visited a given page.
Over time, the rows in pageviews change. For each change, a CDC log is generated in the JSON format. Below is an example CDC log for an UPDATE operation. The op field captures the operation type and “before” and “after” fields capture the column values in the row before and after the update. The source field contains some metadata such as the database, schema and table names. Similar CDC logs are generated per INSERT or DELETE operation. In case of an INSERT, there is no before value and for a DELETE there is no after.
Source definition
As the first step to define a CDC pipeline in DeltaStream, you need to create a “store” to access pageviews CDC logs. This can be done via web UI or by using the CREATE STORE command in the DeltaStream CLI:
Next step is defining a “stream” in DeltaStream on top of pageviews changelog records in pgstore. This stream is used as the CDC source to read CDC logs for data changes in pageviews. The statement below is an example DDL statement to define the CDC source stream for pageviews. This statement includes all the fields in the CDC logs’ JSON records. Depending on the use case, you may add or remove some of the columns.
Once the pageviews_cdc stream is created successfully, you can see that among the relations in DeltaStream and it can be used like any other stream within DSQL queries.
Change Data Capture pipeline definition
Now that the CDC source is defined, you need to define the DSQL query that creates the CDC sink and starts the query to propagate the source data changes into the sink. Assume you have already added a Kafka store in DeltaStream and it is marked as your current store. You can find the details on how you can define and use such a store in this previous blog post. The CREATE STREAM AS SELECT statement (CSAS) can be used to create a new stream backed by a Kafka topic, as the CDC sink, in this store and start running the CDC pipeline. Here is an example of such a CSAS statement:
The above statement creates a new topic, named cdc_sink, in the current Kafka store and starts writing the CDC logs for the changes in pageviews_cdc into it. If you want to use a different name for the sink topic or you want to use an already existing topic, you can add that to the WITH clause using the topic property.
The query in CSAS specifies the structure of the records written into the sink. In the above example, the query selects all columns from the CDC source. Therefore, records in cdc_sink will have the exact same structure as pageviews_cdc records. You can check the CDC logs as being written to sink using the PRINT TOPIC command on cdc_sink:
If you are not interested in adding all the fields in CDC logs to the sink; You can modify the query definition in CSAS to match with your use case. For example, if you are just interested in CDC logs related to the INSERT operations and you want to only capture the new record along with the lsn of the change from PostgreSQL, you can write the CSAS statement as below:
Given that both pageviews_cdc and cdc_sink are defined as streams in DeltaStream, you can simply use them in any DSQL query with other relations to filter, aggregate and join their records and create more complex pipelines.
Get Started with DeltaStream and CDC
CDC is a vital component in modern data management and integration solutions. It is especially valuable in scenarios where maintaining data consistency and keeping downstream systems synchronized with changes in the source data is critical.
In this blog post, we showed how a CDC pipeline can be created in DeltaStream to capture changes in a PostgreSQL data source and propagate them into a Kafka sink in real-time.
DeltaStream provides a comprehensive stream processing platform and can be used to create, manage and secure complex CDC pipelines. It is easy to operate and scales automatically. You can get more in-depth information about DeltaStream features and use cases by checking our blogs series. You can reach out to our team to schedule a demo and start using the system.