21 Nov 2022
Min Read
DeltaStream 101 Part 4 – Data Serialization Formats
So far in our DeltaStream101 blog series, we’ve covered the basics of DeltaStream as well as a couple case studies centered around creating materialized views and processing data from different streaming stores like Apache Kafka and AWS Kinesis. If you’ve missed any of the previous posts, check them out below:
- DeltaStream 101 Part 1 – Basics of DeltaStream
- DeltaStream 101 Part 2 – Streaming Materialized Views for Kafka and Kinesis
- DeltaStream 101 Part 3 – Enriching Apache Kafka Data with Amazon Kinesis
You may recall from previous DeltaStream 101 posts that users create DeltaStream stores on top of streaming storage systems like Apache Kafka and AWS Kinesis. After creating a store, the data that lies within the store ultimately needs to be read and deserialized from bytes for processing. The most popular data formats are JSON, Protocol Buffers (Protobuf), and Apache Avro, all of which are supported by DeltaStream. Each of these data formats require their own serialization/deserialization logic, which can add complexity to the task of working with multiple serialization/deserialization formats. However, with DeltaStream, these complexities are handled behind the scenes, creating a streamlined development process for the user.
In this blog post, we will explore how DeltaStream seamlessly integrates with different data serialization formats, and walk through an example use case.
Imagine that you work for an eCommerce website and you have two streams of data – one that represents transactional data and another that represents customer information. The transactional data is encoded using Protobuf and the customer data is encoded using Avro. The goal is to build a real time analytics dashboard of key performance indicators so your business can visualize the most up to date information about how your products are doing in the marketplace. Let’s also assume that the service that creates the dashboard expects the data to come in JSON format. In our analytics dashboard, we want the following metrics:
- Revenue Metric: real-time dollar sum of all transactions per hour
- Geographic Traffic Metric: real-time count of transactions from customers by state per hour
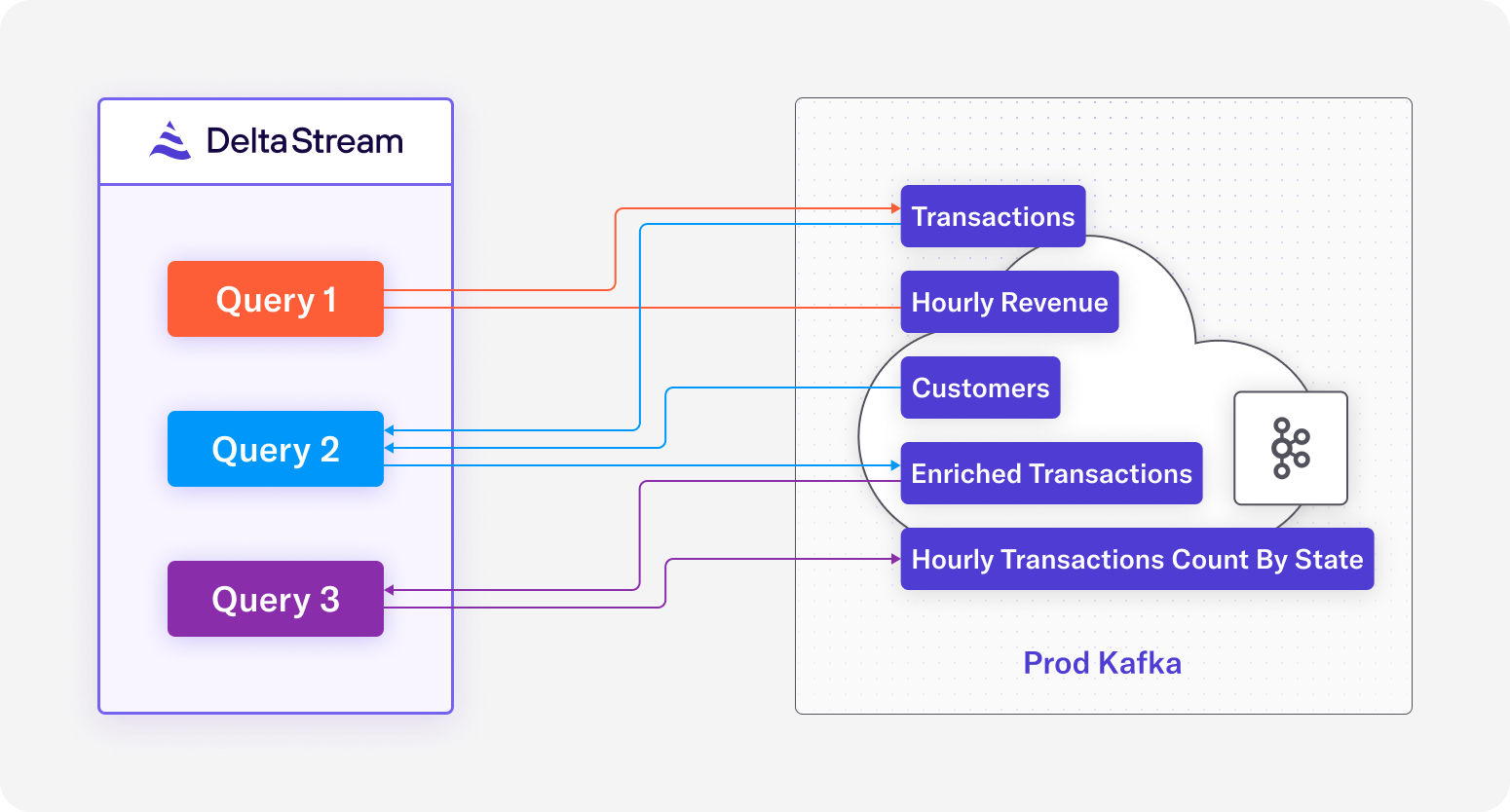
Diagram 1: Overview of SQL pipelines
Query 1 aggregates revenue from transactions,
Query 2 enriches transactions by joining it on customers,
Query 3 aggregates transactions from enriched_transactions by state
Set Up Data Formats: Descriptors and Schema Registries
In our use case we have two streams, the Transactions stream in Protobuf format, and the Customers stream in Avro format. We’ll first cover how to set these streams up as sources for DeltaStream.
Transactions Stream
Below in Code 1a, you’ll see an example of a record from the transactions stream. A new record is created every time a customer buys some item. The record itself contains a “tx_time” timestamp of when the transaction occurred, a “tx_id” which is unique per transaction, fields describing which item was purchased and for how much, and also “customer_id” which is used to identify which customer the transaction belongs to. Code 1b shows the Protobuf message used to create the Protobuf descriptor that serializes and deserializes these transactions.
Code 1a: An example transactions record
Code 1b: Protobuf message for transactions
For the Transactions stream, you can upload the Protobuf descriptor as a DeltaStream descriptor. A DeltaStream descriptor is an object that resources necessary for the streaming SQL query to serialize and deserialize data, such as a Protobuf descriptor, are uploaded to. After creating the DeltaStream descriptor, you can attach it to the relevant DeltaStream topic.
Code 1c: Commands to create and show DeltaStream descriptors
Now, let’s observe the contents of our Protobuf topic before and after we attach a descriptor:
Code 1d: Print DeltaStream topic before attaching descriptor
Code 1e: Command to update DeltaStream topic with descriptor
Code 1f: Print DeltaStream topic after attaching descriptor
Notice how in Code 1d before the DeltaStream descriptor was attached, the contents of the topic are indiscernible bytes. After the DeltaStream descriptor is attached to the topic, the contents are properly deserialized as shown in Code 1e.
Finally, we can define a stream from this topic as shown in DDL 1:
DDL 1: A DDL statement for operating on the transactions records
Customers Stream
Below in Code 2a, you’ll see an example of a record from the customers stream. The data in this stream describes information about a particular customer, and a new record is created each time a customer’s information is updated. In each record, there is a field for “update_time” which is a timestamp of when the update occurred, an “id” which maps to a unique customer, the customer’s name, and the up to date address for the customer. Code 1b shows the Avro schema used to serialize and deserialize the records in the customers stream.
Code 2a: An example customers record
Code 2b: Avro schema for customers
For serialization of Avro records, it’s common to use a schema registry for storing Avro schemas. DeltaStream makes it easy to integrate with an external schema registry. You can import a schema registry by providing a name, the type of the schema registry, and any required connectivity related configuration. The imported schema registry is then attached to a store, so any data from that store can be serialized and deserialized by the schemas in the configured schema registry. Note that even though a schema registry is attached to the store, it operates at the topic level. This means a store can contain both topics with data formats that require the schema registry, and topics that don’t, such as a JSON schema external to the store’s schema registry. The schema registry will simply be used for the topics that require it and ignored for the other topics. Currently, we require a schema registry to be used if your data is serialized with Avro.
Code 2c: Command to create DeltaStream schema registry
Code 2d: Print DeltaStream topic before attaching schema registry
Code 2e: Command to update DeltaStream store with schema registry
Code 2f: Print DeltaStream topic after attaching schema registry
Similar to how we needed the DeltaStream descriptor to deserialize data in transactions, note how the schema registry must be attached to the store to properly deserialize data in customers. In Code 2d, before the schema registry is added to the store, the records in the customers topic are indiscernible. After updating the store with the schema registry, we can see the contents are properly deserialized as shown in Code 2e.
Since the customers data is really keyed data, where information is updated per customer “id”, it makes sense to create a changelog on this topic. We can define that changelog and specify “id” as the primary key as shown in DDL 2:
DDL 2: A changelog DDL to capture the latest customer information from the customers topic
Revenue Metric: real-time dollar sum of all transactions per hour
For our hourly dollar sum revenue metric, we need to perform a windowed aggregation on the transactions data. We’ve already created and attached a descriptor for this topic and a stream relation that represents this topic. From there, in Query 1, we can aggregate dollar sums of all transactions by simply writing a short SQL query:
Query 1: Aggregation of hourly revenue from transactions stream
By default, a new stream created from an existing stream will inherit the properties of the source stream. However, in this query we specify ’value.format’=’json’ in the WITH clause, which signals the output stream to serialize its records as JSON.
We can inspect the results of the new stream using an interactive query, which prints the results to our console:
Geographic Traffic Metric: real-time count of transactions from customers by state per hour
The customers stream defined earlier, provides helpful information to compute geographic traffic information for customers using our eCommerce website, but we also need the transactions stream to generate the number of transactions per state.
We can achieve this by joining the transactions on to the customers information. The persistent SQL statement in Query 2 shows how we can enrich the transactions stream as intended:
Query 2: Enrich transaction records with customers information for the metrics by state
Running a simple interactive query to inspect the results, we can see the enriched stream includes the customer address information with the transaction information:
Using Query 2, we were able to join transactions in Protobuf format with customers in Avro format, and write the result to transactions_enriched in JSON format without worrying about what the format requirements are for each of the source or destination relations. Now that we have the transactions_enriched stream, we can perform a simple aggregation to produce our desired metric:
Query 3: Aggregation of hourly count of unique transactions by state
Inspecting the records in the hourly_tx_count_by_state relation, we can see aggregate transaction counts separated by state and for what time window:
Conclusion
In this post, we demonstrated how DeltaStream makes it easy to work with different serialization formats, whether you need to attach descriptors that describe your data, or link your schema registry. The above example demonstrated how a user can easily set up pipelines in minutes to transform data from one format to another, or to join data available in different data formats. DeltaStream eliminates the need or complexity of managing streaming applications and dealing with complicated serialization or deserialization logic so the user can focus on what matters most: writing easy-to-understand SQL queries and generating valuable data for real-time insights or features.
Expect more blog posts in the coming weeks as we showcase more of DeltaStream’s capabilities for a variety of use cases. Meanwhile, if you want to try this yourself, you can request a demo.



