14 Nov 2023
Min Read
Key Components of a Modern Data Stack: An Overview
Data is one of the most valuable assets of any company in the digital age. Drawing insights from data can help companies better understand their market and make well informed business decisions. However, to unlock the full potential of data, you need a data stack that can collect, store, process, analyze, and act on data efficiently and effectively. When considering a data stack, it’s important to understand what your needs are and how your data requirements may change in the future, then make decisions that are best suited for your particular business. For almost every business, making the most out of data collection and data insights are essential, and you don’t want to find yourself stuck with a legacy data system. Data systems can quickly go out of date and updating to new emerging technologies can be painful. Using modern cloud-based data solutions is one way you can help keep your data stack flexible, scalable, and ultimately save time and money down the road.
In this blog post, we’ll cover the benefits of building a modernized data stack, the main components of a data stack, and how DeltaStream fits into a modern data stack.
What makes a Modern Data Stack and Why You Need One
The modern data stack is built on cloud-based services and low-code or no-code tools. In contrast to legacy systems, modern data stacks are typically built in a distributed manner and aim to improve on the flexibility, scalability, latency, and security of older systems.
How we build a data stack to manage and process data has developed and morphed greatly in the last few years alone. Changing standards, new regulations, and the latest tech have all played a role in how we handle our data. Some of the core properties of a modern data stack include being:
- Cloud-based: A cloud-based product is something that users can pay for and use over the internet, whereas before users would have to buy and manage their own hardware. The main benefit for users is scalability of their applications and reduced operational maintenance. Modern data solutions offer elastic scalability, meaning users can easily increase or decrease the resources running for their applications by simply adjusting some configuration. More recently, modern data solutions have been offering a serverless option, where users don’t need to worry about resources at all, and automatic scaling is handled behind the scenes by the solution itself. Compare this with legacy systems, where scaling up requires planning, hardware setup, and maintenance of the software and new hardware. Elastic scaling enables users to be flexible with the workloads they plan to run, as resources are always available to use. To ensure availability of their products, modern data solutions typically guarantee SLAs, so users can expect these products to work without worrying about system maintenance or outages. Without the burdens of resource management and system maintenance, users can completely focus on writing their applications, which will improve developer velocity and allow businesses to innovate faster.
- Performant: In order for modern data solutions to be worthwhile, they need to be performant. Low latency, failure recovery, and security are all requirements for modern data solutions. While legacy systems may have been sufficient to meet the standards of the past, not all of them have evolved to meet the requirements of data workloads today. Many of the current modern data products utilize the latest open-source technologies in their domain. For example, Databricks utilizes and contributes back to the Apache Spark project, Confluent does the same for Apache Kafka, and MongoDB does the same for the MongoDB open source project. For modern data solutions that aren’t powered by open source projects, they typically feature advanced state-of-the-art software and provide benchmarks on how their performance compares to the status quo. Modern data solutions make the latest technologies accessible, enabling businesses to build powerful tools and applications that get the most out of their data.
- Easy to use: The rapid development and advancement of technologies to solve emerging use cases has led to the most powerful tech to also become the most complex and specialized. While these technologies have made it possible to solve many new use cases, they’re oftentimes only accessible to a handful of experts. Because of this, the modern trend is towards building democratized solutions that are low-code and easy to use. That’s why modern solutions abstract away the complexities of their underlying tech and expose easy to use interfaces to users. Consider AWS S3 as an example, users can use the AWS console to store or retrieve files without writing any code. However, behind the scenes, there is a highly complex system to provide strong consistency guarantees, high availability, scale indefinitely, and provide a low-latency experience for users. Businesses using modern data solutions no longer need to hire or train experts to manage these technologies, which ultimately saves time and money.
Components of a Data Stack
At a high level, a modern data stack consists of four components: collection, storage, processing and analysis/visualization. While most modern data products loosely fit into a single component, it’s also not uncommon for solutions to span multiple components. For example, data warehouses such as Databricks and Snowflake act as both Data Storage (with data governance) and Data Processing.
- Data Collection: These are services or systems that ingest data from your data sources into your data platform. This includes data coming from APIs, events from user facing applications, and data from databases. Data can come structured or unstructured and in various data formats.
- Data Storage: These are systems that hold data for extended periods of time, either to be kept indefinitely or for processing later on. This includes databases like MongoDB, or streaming storage platforms like RedPanda and Kinesis. Data warehouses and data lakes such as Snowflake and AWS S3 can also be considered data storage.
- Data Processing: These are the systems that perform transformations on your data, such as enrichment, filtering, aggregations, and joins. Many databases and data warehouses have processing capabilities, which is why you may see some products in multiple categories below. For example Snowflake is a solution where users can store their data and run SQL queries to transform the data in their tables. For stream processing use cases, users may look at products like DeltaStream that use frameworks such as Apache Flink to handle their processing.
- Data Analysis and Visualization: These are the tools that enable you to explore, visualize, and share data insights. These include BI platforms, analytics software, and chart building software. Some popular tools include Tableau and Microsoft Power BI among others. Data analysis and visualization tools can help users draw insights from their data, discover patterns, and communicate findings.
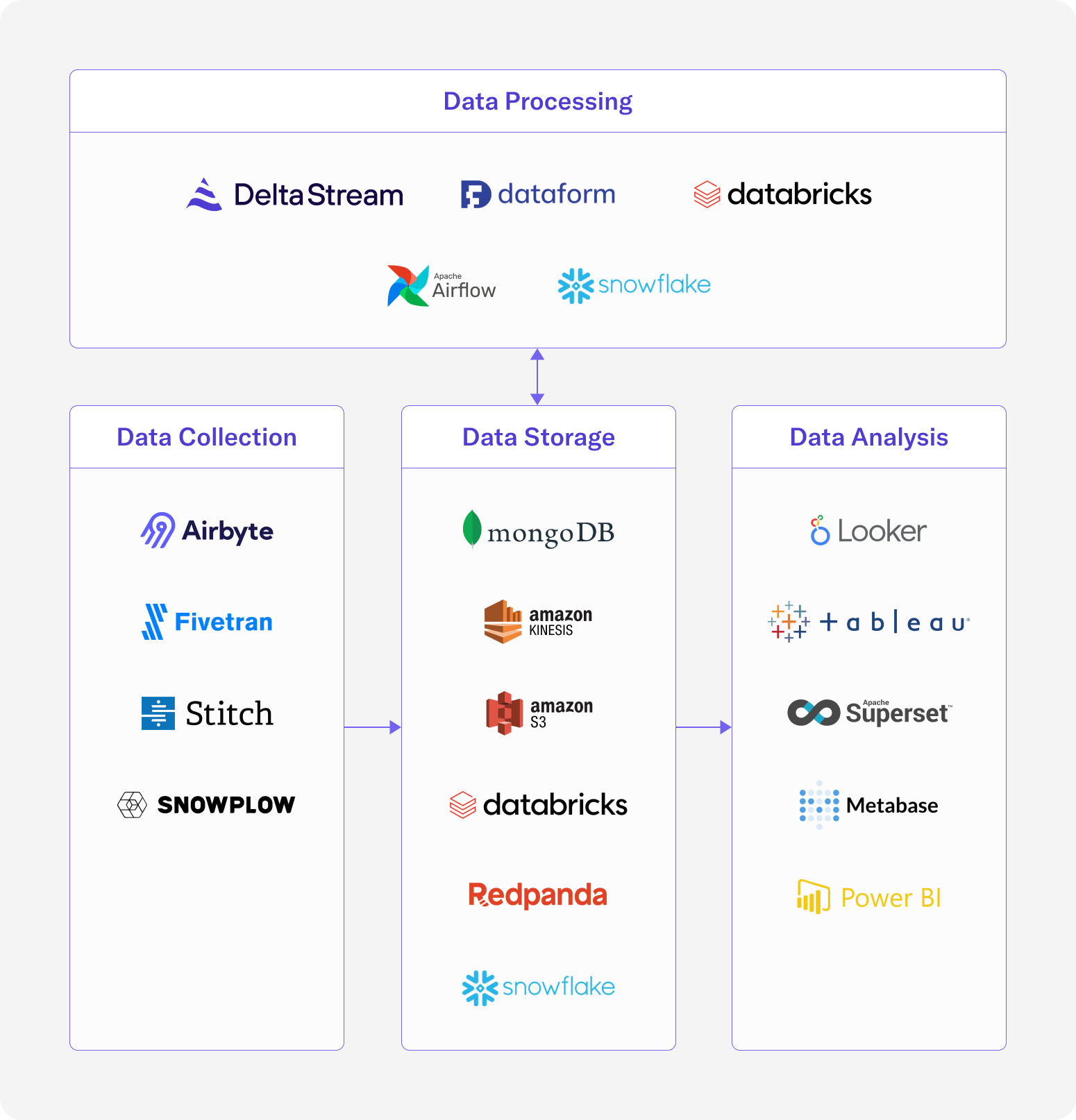
Overview of the current landscape of modern data technologies
How DeltaStream fits into your Modern Data Stack
DeltaStream is a serverless data platform that unifies, governs, and processes real-time data. DeltaStream acts as both an organizational and compute layer on top of users data resources, specifically streaming resources. In the modern data stack, DeltaStream fits in the Data Storage and Data Processing layers. In particular, DeltaStream makes it easier to manage and process data for streaming and stream processing applications.
In the Data Storage layer, DeltaStream is a data platform that helps users properly manage their data through unification and governance. By providing proper data management tools, DeltaStream helps make the entire data stack more scalable and easier to use, allowing developers to iterate faster. Specifically, DeltaStream improves on the flat namespace model that most streaming storage systems, such as Kafka, currently have. DeltaStream instead uses a hierarchical namespace model such that data resources exist within a “Database” and “Schema”, and data from different storage systems can exist within the same database and schema in DeltaStream. This way the logical representation of your streaming data is decoupled from the physical storage systems. Then, DeltaStream provides Role Based Access Control (RBAC) on top of this relational organization of data so that roles can be created for certain permissions and users can inherit the roles that they’ve been granted. While DeltaStream isn’t actually storing any raw data itself, providing data unification and data governance to otherwise siloed data makes managing and securing all of a user’s streaming data easier. The graphic below is a good representation of DeltaStream’s federated data governance model.
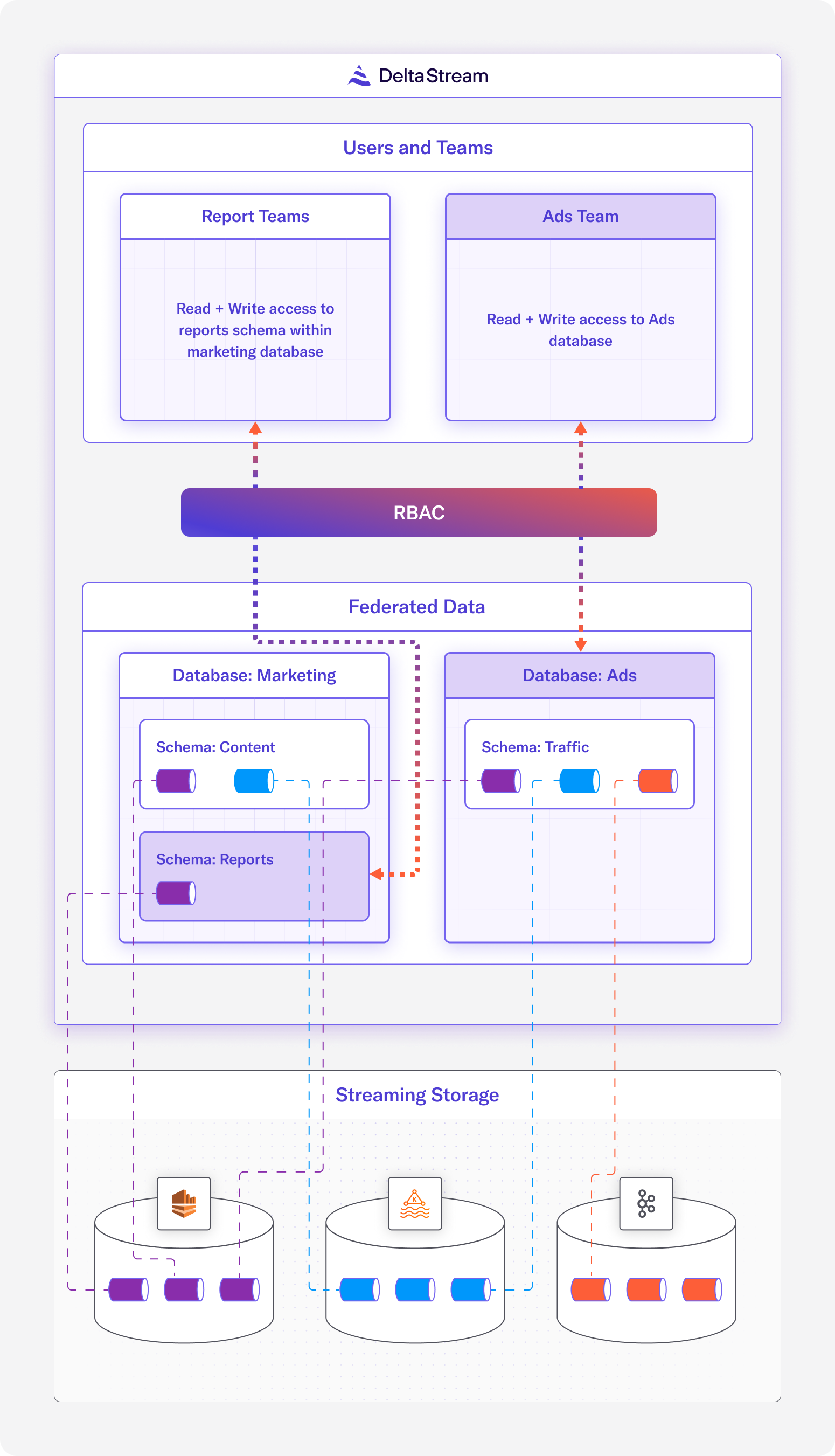
DeltaStream federated data governance
In the Data Processing layer, DeltaStream provides an easy to use SQL interface to define long lived stream processing jobs. DeltaStream is a serverless platform, so fault tolerance, deployment, resource scaling, and operational maintenance of these queries are all taken care of by the DeltaStream platform. Under the hood, DeltaStream leverages Apache Flink, which is a powerful open source stream processing framework that can handle large volumes of data and supports complex data transformations. For DeltaStream users, they get all the benefits of Flink’s powerful stream processing capabilities without having to understand Flink or write any code. With simple SQL queries, users can deploy long-lived stream processing jobs in minutes without having to worry about scaling, operational maintenance, or the complexities of stream processing. This fits well with the scalable, performant, and easy to use principles of modern data stacks.
Conclusion
In this blog post we covered the core components of a data stack and discussed the benefits in investing in a modern data stack. For streaming storage and stream processing, we discussed how DeltaStream fits nicely in the modern data stack for unifying, governing, and processing data. DeltaStream’s integrations with non-streaming databases and data warehouses such as PostgreSQL, Databricks, and Snowflake make it a great option to run alongside these already popular modern data products. If you have any questions about modern data stacks or are interested in learning more about DeltaStream, reach out to us or schedule a demo.