01 Nov 2022
Min Read
DeltaStream 101 Part 3 – Enriching Apache Kafka Topics with Amazon Kinesis Data Streams
In Part 1 of our DeltaStream 101 series, we uncovered how DeltaStream connects to your existing streaming storage, Apache Kafka or Amazon Kinesis, using the DeltaStream Store. In this part of the series, we’re going to expand on that concept and use a real-life example around how you can enrich, filter, and aggregate your data between different streaming stores to simplify your product’s data needs.
As you may remember, we created a clicks stream backed by a clicks topic in an Apache Kafka cluster, and ran an aggregate query to count the number of clicks per URL and device type. In this post, we’re going to enrich the clicks stream with the user data. The user data will come from an Amazon Kinesis data stream where we will declare a users changelog on it in DeltaStream. Changelog represents a stream of upserts or deletions to our users’ information. This allows the resulting enriched stream(s) to include a registered user information as well. Using the enriched user clicks, we’re going to aggregate the number of clicks per URL and region.
This pipeline is demonstrated in Diagram 1:
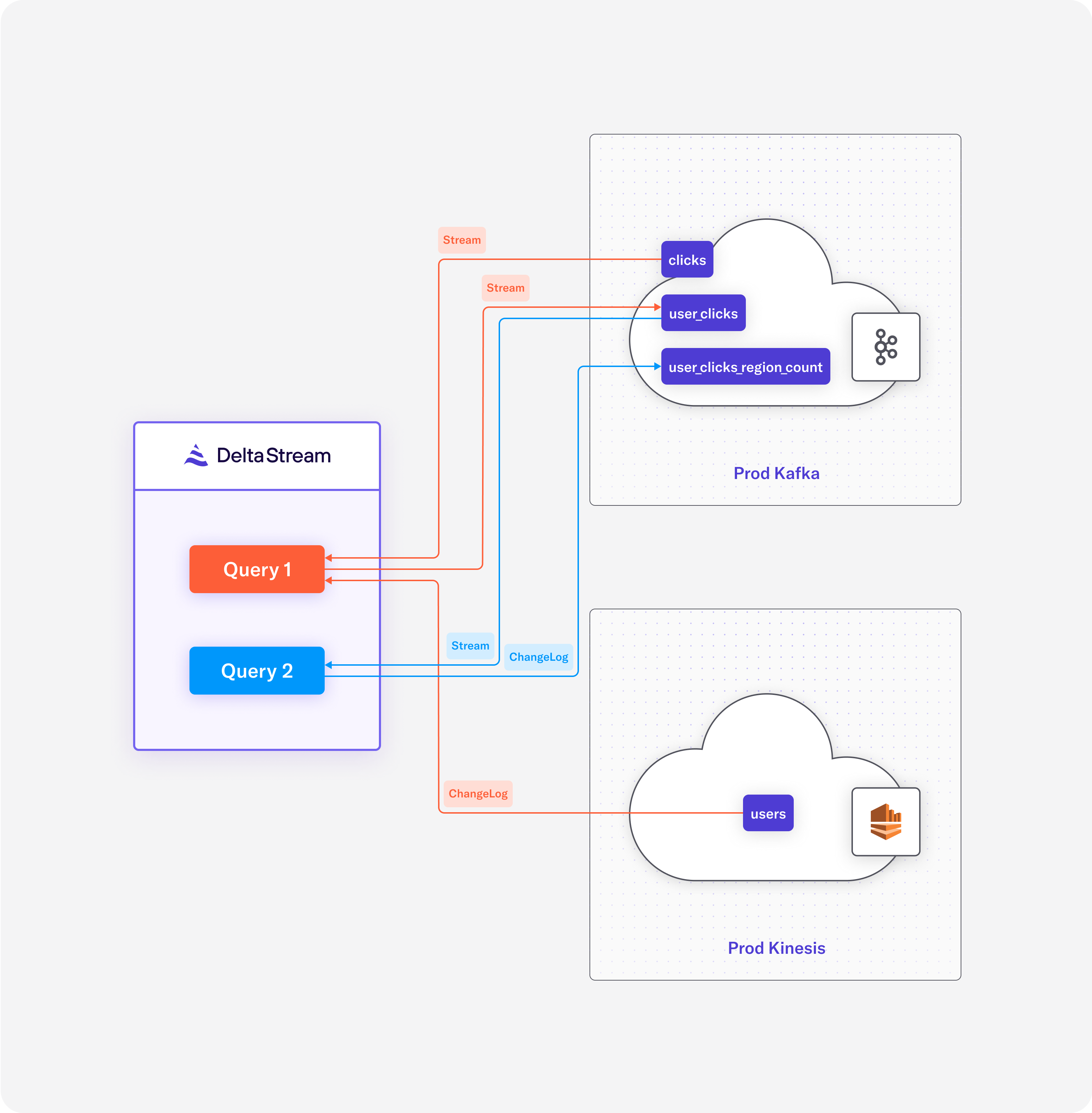
Diagram 1: Query 1 enriches the clicks stream in Apache Kafka with users changelog in Amazon Kinesis, and Query 2 aggregates users clicks per region.
Accessing the Enrichment Information
First, we need to set up a store to access our Amazon Kinesis data streams:
The following statement creates a store named prod_kinesis with the provided configurations:
Once we declare the prod_kinesis store, as with any DeltaStream store, we can inspect our Kinesis data stream, users, that holds our user information by printing it as a topic:
Printing the users topic shows the content as followed:
Using the values in the data stream, we can create a changelog using the following Data Definition Language (DDL) statement. Note that we’re using the same DeltaStream Database and Schema, clickstream_db.public, that we declared in part 1 of this series for the newly declared changelog:
Every CHANGELOG defines a PRIMARY KEY as context around the changes in a changelog.
Enriching the Clicks
Let’s now use our user information to enrich the click events in the clicks stream, and publish the results back into the prod_kafka store from our previous post in this series:
Query 1: Enriching product clicks with users information to be able to expand the clicks report with region
Using just a single persistent SQL statement, Query 1, we were able to:
- Enrich the click events by joining the clicks and users relations on the userid column from Kafka and Kinesis, respectively.
- Project only the non-PII data from the enriched clicks stream, since we don’t want the sensitive user data to leave our Kinesis store.
- and, write back the result of the enrichment into the prod_kafka store, while creating a new user_clicks stream backed by a Kafka topic, configured the same as the underlying topic for the clicks stream.
Since we’re joining a stream with a changelog, a temporal join is implied. In other words, click events are enriched with the correct version of the user information, updating the resulting user_clicks stream and any other downstream streams with the latest user information.
We can inspect the result of the temporal join between clicks and users using the following query:
Showing the following records in the user_clicks stream:
Clicks per URL and Region
We can now create a new persistent SQL statement, Query 2, to continuously aggregate user_clicks and count the number of clicks per URL per region, and publish the result back into our Kafka store, prod_kafka, under a new url_region_click_count relation, which is a changelog:
Query 2: Aggregating number of clicks per URL and region
User Experience and Beyond
In this post, we looked at a case study where we enriched, transformed and aggregated data from multiple streaming storages, namely, Apache Kafka and Amazon Kinesis. We built a pipeline that was up and running in seconds, without the need for writing streaming applications that could take much longer to develop and require ongoing maintenance. Just a simple example of how DeltaStream make it possible for developers to implement complex streaming applications.