24 Apr 2024
5 Min Read
Prepare Data for ClickHouse Using Apache Flink
ClickHouse and Apache Flink are two powerful tools used for high-performance data querying and real-time data processing. By using these tools together, businesses can significantly improve the efficiency of their data pipelines, enabling data teams to get insights into their datasets more quickly.
ClickHouse is a fast and resource efficient column-based database management system (DBMS). It specializes in online analytical processing (OLAP) and can handle many queries with minimal latency. With ClickPipes, users who have streaming data, such as data in Apache Kafka, can easily and efficiently build ClickHouse tables from their Kafka topics.
Apache Flink is a stream processing framework that allows users to perform stateful computations over their real-time data. It is fast, scalable, and has become an industry standard for event time stream processing. As a system with a rich connector ecosystem, Flink also integrates easily with Apache Kafka.
Typical Flink and ClickHouse Architecture
ClickHouse and Flink have been used together across the industry at companies like GoldSky, InstaCart, Lyft, and others. The typical infrastructure is as follows:
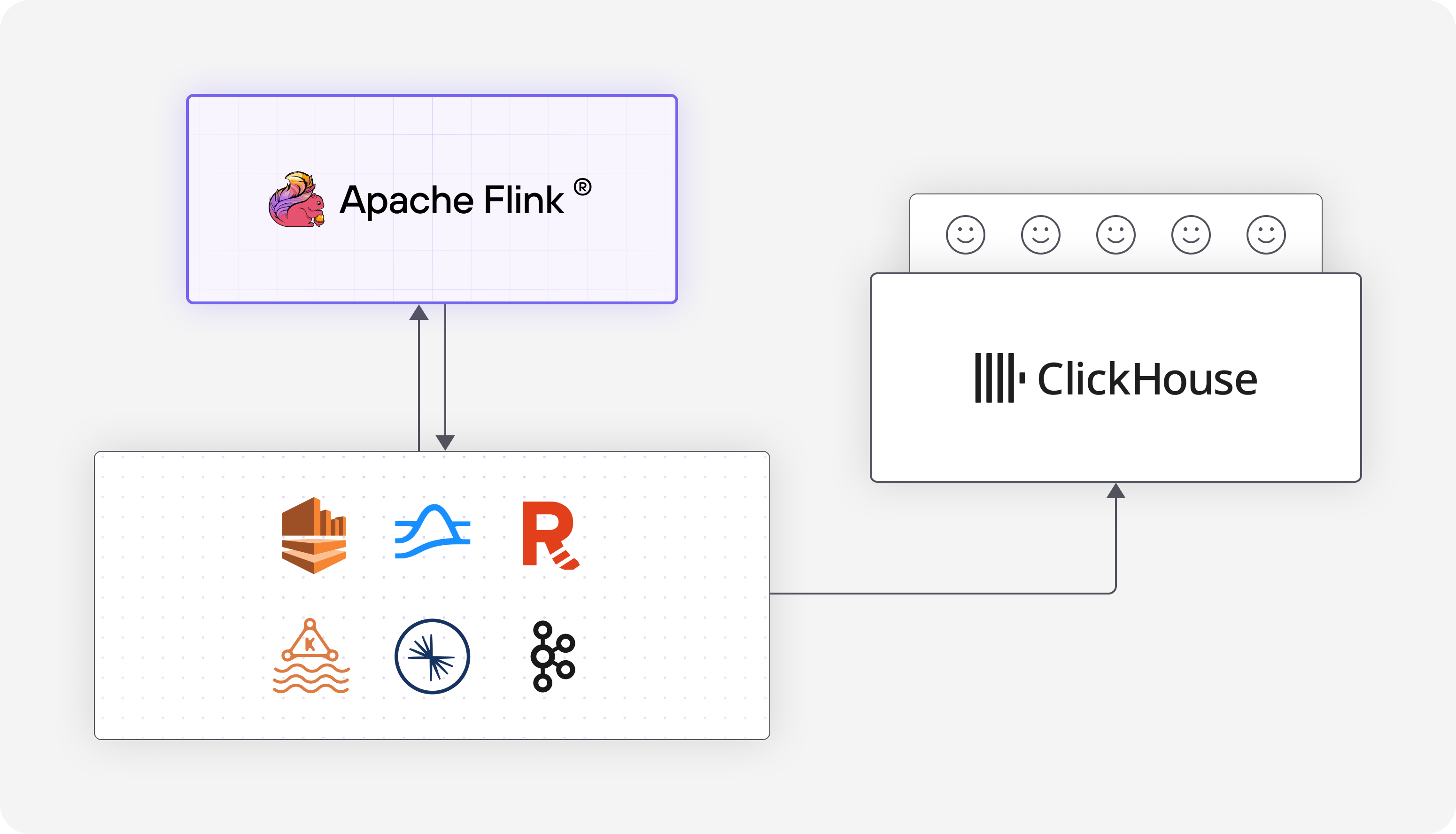
- Data from user product interactions, backend services, or database events via CDC are produced to a streaming data storage system (e.g. Kafka, Kinesis, Pulsar).
- Data in streaming storage is ingested by Flink, where it can be cleaned, filtered, aggregated, or otherwise sampled down.
- Flink produces the data back to the streaming storage where it is then loaded into ClickHouse via ClickPipes.
- Data scientists and data engineers can query ClickHouse tables for the latest up-to-date data and take advantage of ClickHouse’s high-performance querying capabilities.
How Flink Adds More Value to ClickHouse
You may be wondering why Flink is needed in this architecture. Since ClickPipes already enable users to load data from streaming stores directly into ClickHouse, why not just skip Flink altogether?
The answer is that although ClickHouse is a highly optimized DBMS for querying data, performing queries such as aggregations over large data sets still forces the ClickHouse query engine to bring the relevant columns of every entry into memory to perform the aggregation, which can affect query latency. In this ClickHouse blog, they listed that the following query took 15 seconds to complete:
One feature that ClickHouse has to reduce latencies for commonly run queries is Materialized Views (ClickHouse docs on creating Views). In their blog, they first created a materialized view to compute the result, then ran the same query against the materialized view. The result was computed in 3ms as opposed to 15s.
For users who load their raw streaming data directly into a ClickHouse table, they can utilize materialized views to transform and prepare the data for consumption. However, these views need to be maintained by ClickHouse, and this overhead can add up, especially if a lot of views are being created. Having too many materialized views and putting too much computational load onto ClickHouse can lead to performance degradation, resulting in lower throughputs for writes and increased latencies for querying data.
Introducing a stream processing engine, such as Flink, lets users transform and prepare streaming data before loading it into ClickHouse. This helps alleviate pressure from ClickHouse and allows users to take advantage of the features that come with Flink. For instance, ClickHouse is known to struggle with queries that include joins. By using Flink, datasets can be joined and transformed in Flink before being loaded into ClickHouse. This way, instead of resources being diverted into data preparation queries, ClickHouse can focus on serving high-volume OLAP queries, which it excels at. Since Flink is built to be able to efficiently handle large and complex stream processing workloads, offloading complex computations from ClickHouse to Flink ultimately makes data available more quickly and reduces computational expenses.
Building with Cloud Products
There are many benefits to utilizing this architecture for real-time analytics, but the reality for many companies is that the systems involved require too many resources to maintain and operate. This is the classic build vs buy dilemma. If your company does decide to go with the buy route, here are the cloud offerings we recommend for the 3 main components of this architecture:
- Streaming Storage: For Kafka compatible solutions, Confluent Cloud, RedPanda, Amazon MSK, and WarpStream are all viable options with different tradeoffs. Other streaming storage solutions include Amazon Kinesis and StreamNative for managed Pulsar among others.
- Stream Processing: DeltaStream is a great serverless solution to handle stream processing workloads. Powered by Apache Flink, DeltaStream users can benefit from the capabilities of Flink without having to worry about the complexity of learning, managing, and deploying Flink themselves.
- ClickHouse: ClickHouse Cloud is a serverless ClickHouse solution that is simple to set up, reliable, and has an intuitive SQL-based user interface.
Conclusion
In this post, we discussed a popular architecture involving Kafka, Flink, and ClickHouse that many companies have been adopting across the industry. These systems work together to enable high-performance analytics for real-time data. In particular, we touched on how Flink complements both Kafka and ClickHouse in this architecture.
If you’re looking for a cloud-based stream processing solution, DeltaStream is a serverless platform that is powerful, intuitive, and easy to set up. Stay tuned for our next blog post as we cover a use case using this architecture, with DeltaStream in place of Flink. Meanwhile, if you want to give DeltaStream a try yourself, you can sign up for a free trial.