22 Mar 2023
Min Read
When to use Streaming Analytics vs Streaming Databases
Event streaming infrastructure has become an important part of modern data stack in many organizations enabling them to rapidly ingest and process streaming data to gain real-time insight and take actions accordingly. Streaming storage systems such as Apache Kafka provide a storage layer to ingest and make data streams available in real-time. Streaming analytics(stream processing) systems and streaming databases are two platforms enabling users to gain real-time insight from their data streams. However, each of these systems is suitable for different use cases and one system alone may not be the right choice for all of your stream processing needs. In this blog, we will provide a brief introduction on streaming analytics(stream processing) and streaming database systems and discuss how they work and what use cases each of them is suitable for. We then show how DeltaStream can provide capabilities of both these systems on one unified platform along with more capabilities unique to DeltaStream.
What is Streaming Analytics?
Streaming analytics, also known as stream processing, continuously processes and analyzes event streams as they arrive. Streaming analytics systems do not have their own storage but provide a compute layer on top of other storage systems. These systems usually read data streams from streaming storage systems such as Apache Kafka, process it and write the results back to the streaming storage system. Streaming analytics systems provide both stateless(e.g., filtering, projection, transformation) and stateful(e.g., aggregation, windowed aggregation, join) processing capabilities on data streams. Many of them also provide a SQL interface where users can express their processing logic in familiar SQL statements. Apache Flink, Kafka Stream/Confluent’s ksqlDB and Spark Streaming are some of the commonly used streaming analytics(stream processing) platforms. The following figure depicts a high level overview of a streaming analytics system and its relation with streaming stores.
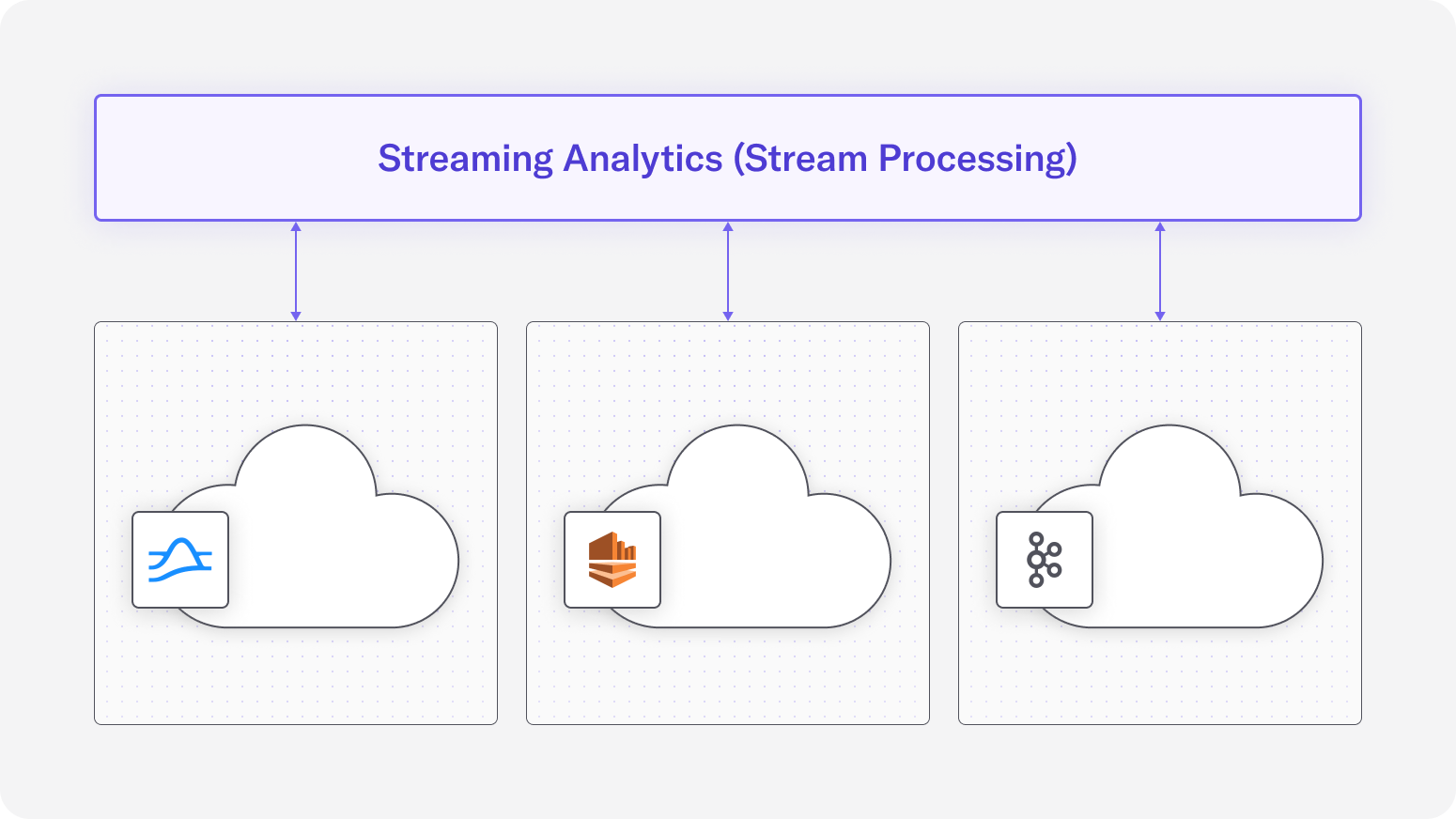
Streaming analytics systems are used in a wide variety of use cases. Building real-time data pipelines is one of the main use cases for the streaming analytics systems where data streams are ingested from source stores, processed and written into destination stores. Streaming data integration, real-time ML pipelines and real-time data quality assurance are just a few solutions you can use real-time data pipelines powered by streaming analytics systems. Other use cases for streaming analytics systems include their use in data mesh deployment and building event-driven microservices.
An important characteristic of streaming analytics systems is the focus on processing. In these systems, queries also known as jobs are a fundamental part of the platform. They provide fine grained control over these queries where users can start, pause and terminate queries individually without having to make any changes in the sources and sinks of those queries. The focus on queries is one of the main differences between streaming analytics and streaming databases as we explore them in the next section.
What is a Streaming Database?
Streaming databases combine stream processing and the serving of results in one system. Unlike streaming analytics systems, that are compute-only platforms and don’t have their own storage, streaming databases include their own storage where the results of continuous computations are stored and served to user applications. Materialized views are one of the foundational concepts in streaming databases that represent the result of continuous queries that are updated incrementally as the input data arrives. These materialized views are then available to query through SQL.
The following figure depicts a high level view of a streaming database architecture.
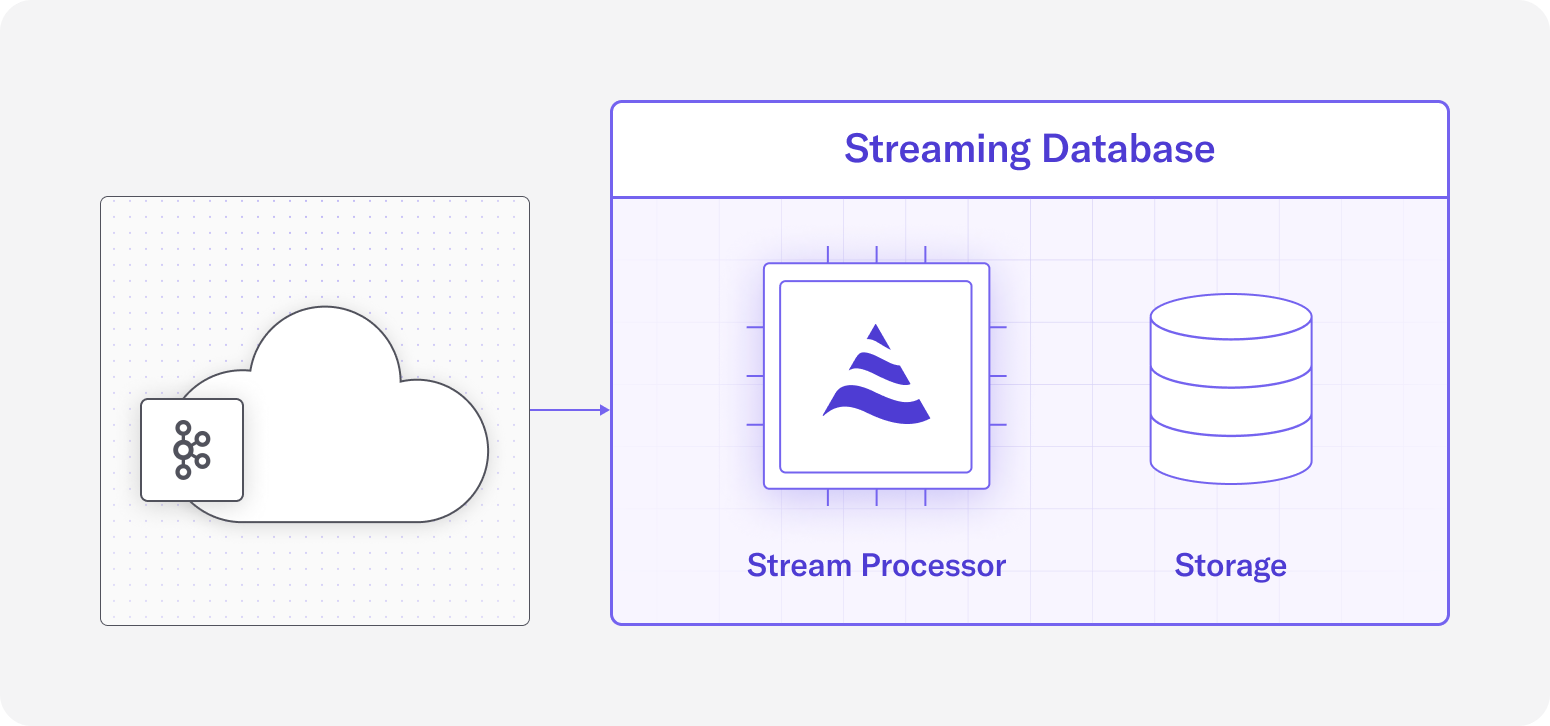
The role of queries is different in streaming databases. As mentioned above, continuous queries are a fundamental part of streaming analytics systems, however, streaming databases don’t provide for fine grain control over queries. In streaming databases, the life cycle of continuous queries are attached to the materialized views and they are started and terminated implicitly by creating and dropping materialized views. This significantly limits the capabilities of users to manage such queries which is an essential part of building and managing streaming data pipelines. Therefore, streaming analytics systems are much more suited to build real-time data pipelines than streaming databases.
While streaming databases may not be the right tool for building real-time streaming pipelines, the incrementally updated materialized views in streaming databases can be used to serve real-time data to power user-facing dashboards and applications. They can also be used to build real-time feature stores for machine learning use cases.
Can we have both? With DeltaStream, yes
While streaming analytics systems are ideal for building real-time data pipelines, streaming databases are great in building incrementally updated materialized views and serving them to applications. Customers are left having to choose between two systems or even worse buy multiple solutions. The question is, can you have one system to reduce complexity and provide a comprehensive and powerful platform to build real-time applications on streaming data? The answer, as you expected, is Yes!
DeltaStream does this seamlessly as a serverless service. As the following diagram shows, DeltaStream provides capabilities of both streaming analytics and streaming databases along with additional features to provide a complete platform to manage, process, secure and share streaming data.
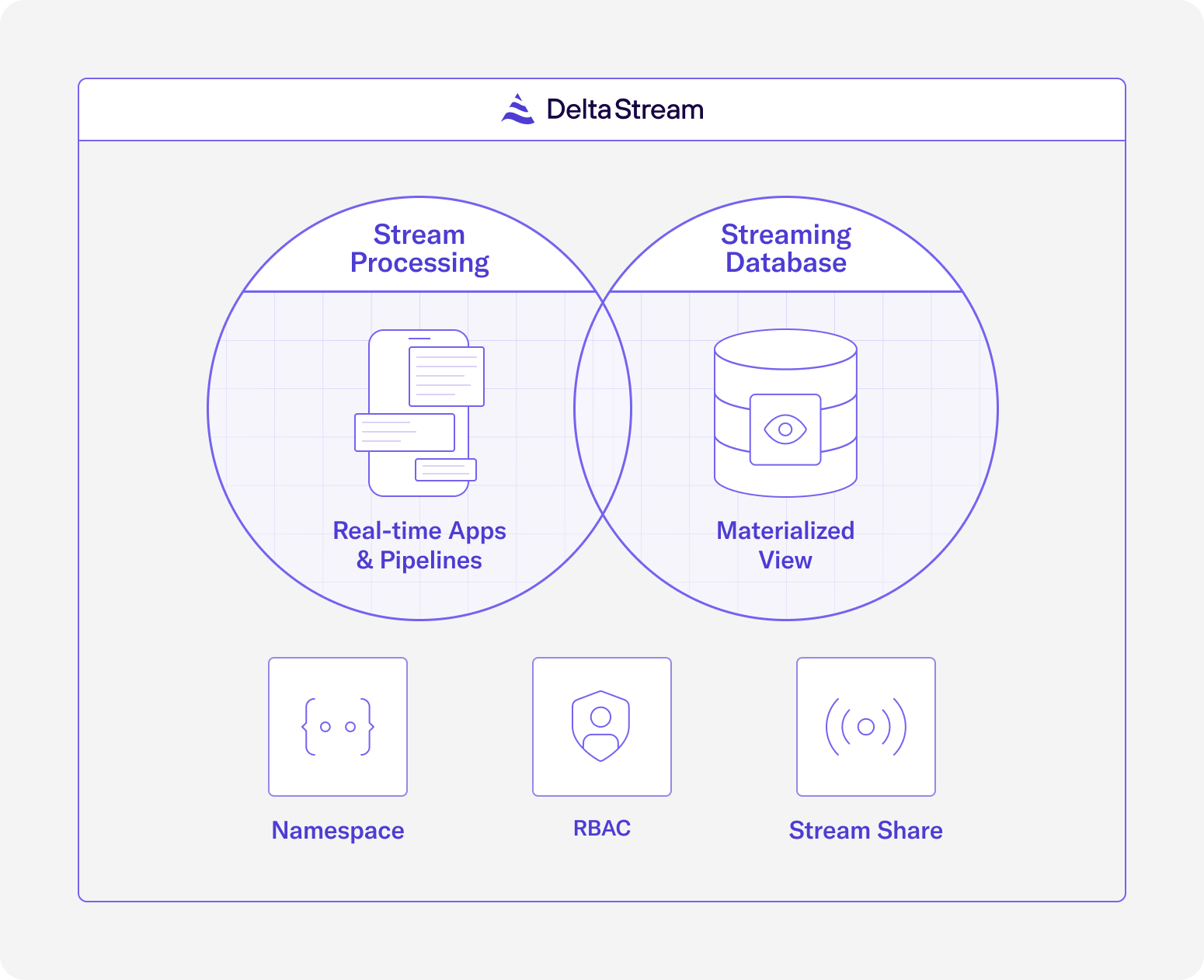
Using DeltaStream’s SQL interface you can build streaming applications and pipelines. You can also build continuously updated materialized views and serve them to applications and dashboard in real-time. DeltaStream also provides fine grained control on continuous queries where you can start, restart and terminate each query. In addition to compute capabilities on streaming data, DeltaStream also provides familiar hierarchical name-spacing for your streams. In DeltaStream, you declare relations such as streams and changelogs on your streaming data such as Apache Kafka topics and organize them in databases and schemas the same way you organize tables in traditional databases. You can then control access to your streaming data with the familiar Role-based Access Control (RBAC) mechanism that you would use in traditional relational databases. This significantly simplifies using DeltaStream since you don’t need to learn a new security model for your streaming data. Finally, DeltaStream enables users to securely share real-time data with internal and external users.
So if you are using streaming storage systems such as Apache Kafka(Confluent Cloud, AWS MSK or any other Apache Kafka) or AWS Kinesis, you should check out DeltaStream as the platform for processing, organizing and securing your streaming data. You can schedule a demo where you can see all these capabilities in the context of a real world streaming application.



