23 Jun 2025
Min Read
Stream Smarter, Spend Less: Shift-Left with DeltaStream and Cut Snowflake Costs by 75%
Snowflake is one of the most powerful cloud data platforms available today. But as organizations increasingly rely on it to power business intelligence, AI, and real-time applications, many are discovering a costly tradeoff. Using Snowflake as the primary engine for all ELT (Extract, Load, Transform) processing can quickly balloon cloud spend.
Every Dynamic Table refresh, every intermediate table, and every downstream aggregation adds up—especially when data volumes or update frequencies grow.
This is why a growing number of modern data teams are shifting left to simplify streaming ETL and slash compute and storage bills.
Why Shift Left?
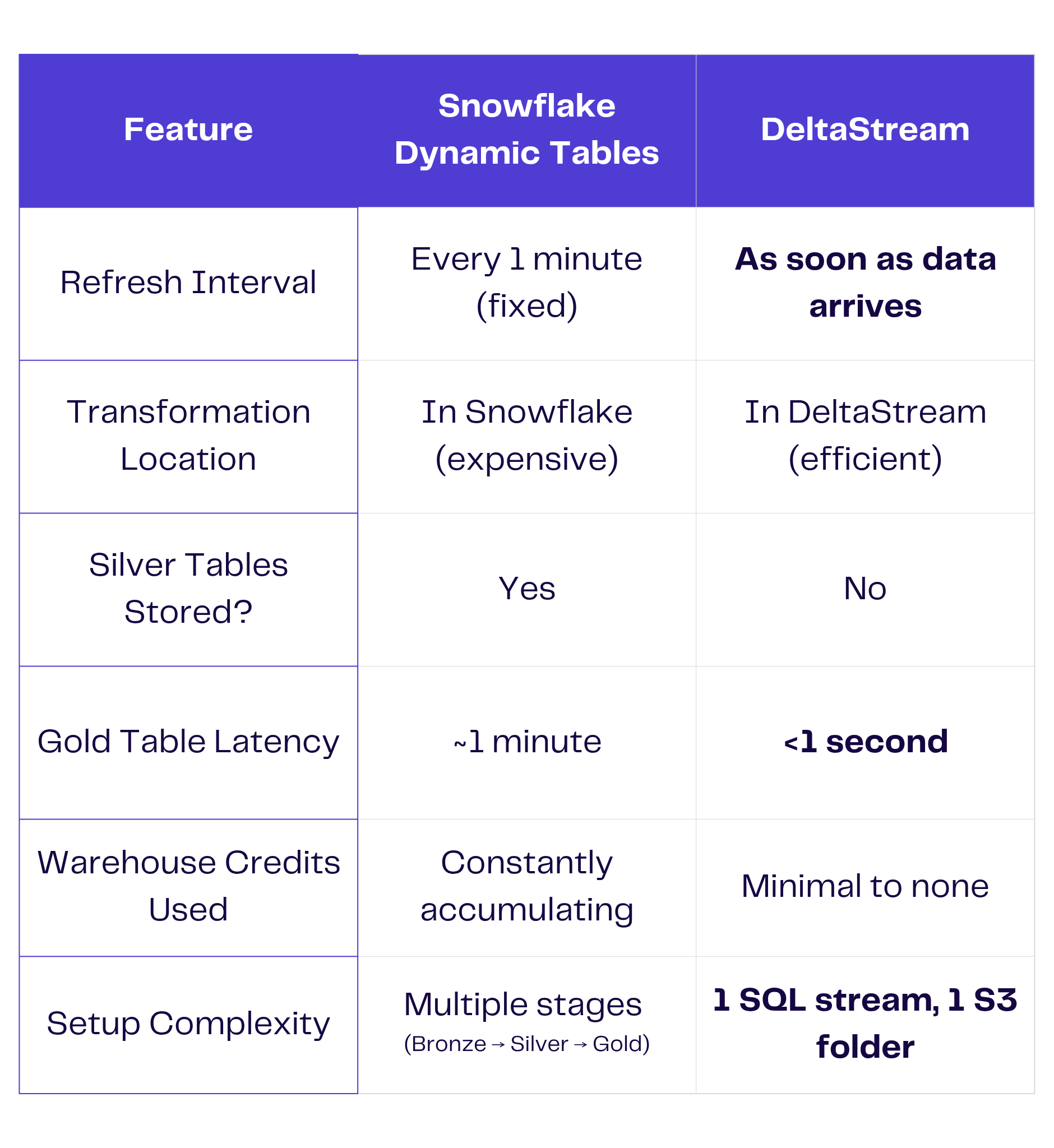
Most pipelines today follow an ELT model: extract raw data, land it in Snowflake, then transform it using tools like Dynamic Tables. While convenient, this pattern introduces hidden inefficiencies. You pay to store intermediate layers—often called Bronze and Silver tables—and rack up warehouse credits with every scheduled refresh. And because those transformations are tied to batch-based triggers, you’re often stuck waiting minutes (or longer) for updated insights.
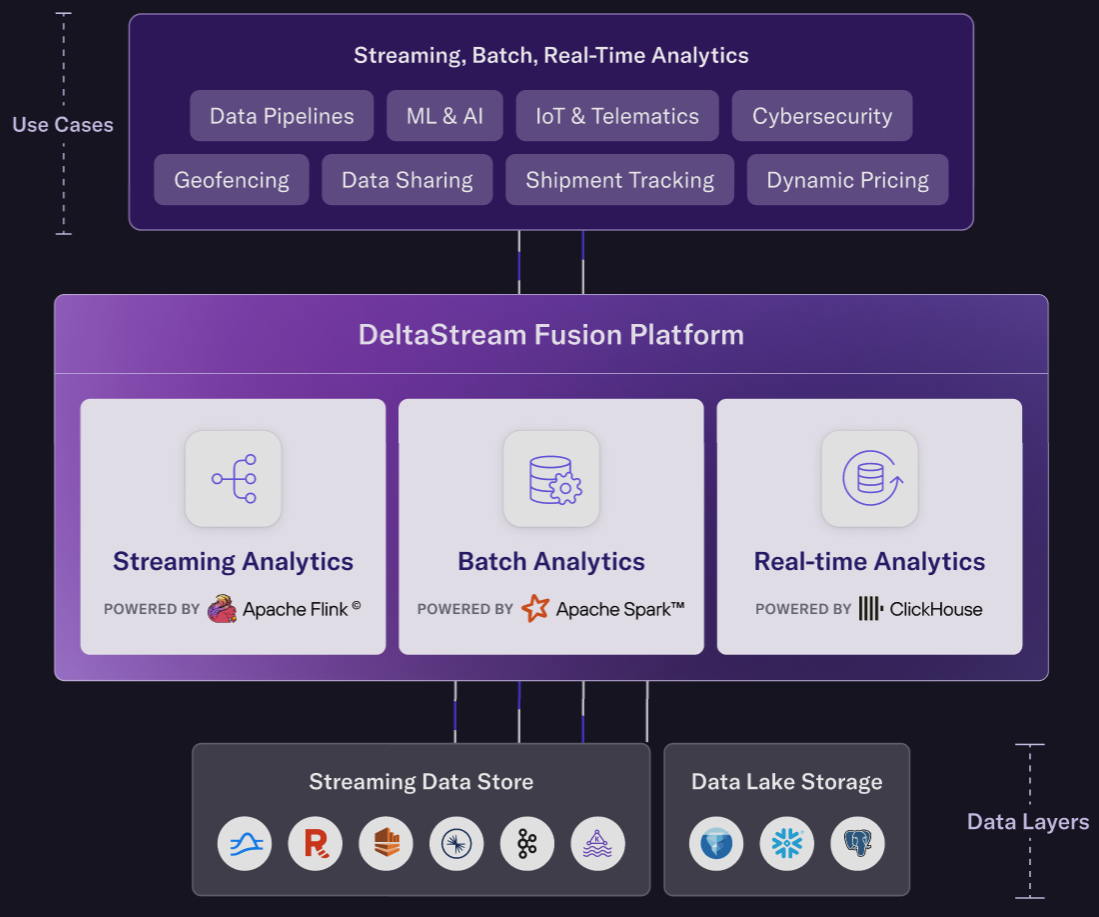
DeltaStream offers a better way. By shifting left, teams can move from ELT to ETL, transforming data before it hits the warehouse. DeltaStream processes raw files as they land—cleaning, enriching, and aggregating them in motion. With just SQL, teams can build real-time pipelines that send only the final, analytics-ready results—Gold tables—into Snowflake. The result? A leaner, faster, and far more cost-effective architecture.
A Real-World Benchmark Using NYC Taxi Data
To prove the difference, we ran a 24-hour benchmark using NYC Yellow Taxi trip data. We tested two different pipeline strategies: one with Snowflake doing all the transformation work (ELT), and another where DeltaStream handled real-time transformations before the data reached Snowflake (ETL). In the Snowflake path, data landed in raw form and passed through multiple Dynamic Tables to get cleaned and enriched. Each table refreshed every minute, consuming compute resources even when no new data arrived. The result was a full transformation pipeline inside Snowflake—functional, but costly.
In the DeltaStream path, we ingested raw data directly from S3 into Kafka using a simple SQL statement. DeltaStream then joined and enriched the data in real time, skipping intermediate Silver tables altogether. Only the final Gold aggregates were streamed into Snowflake.
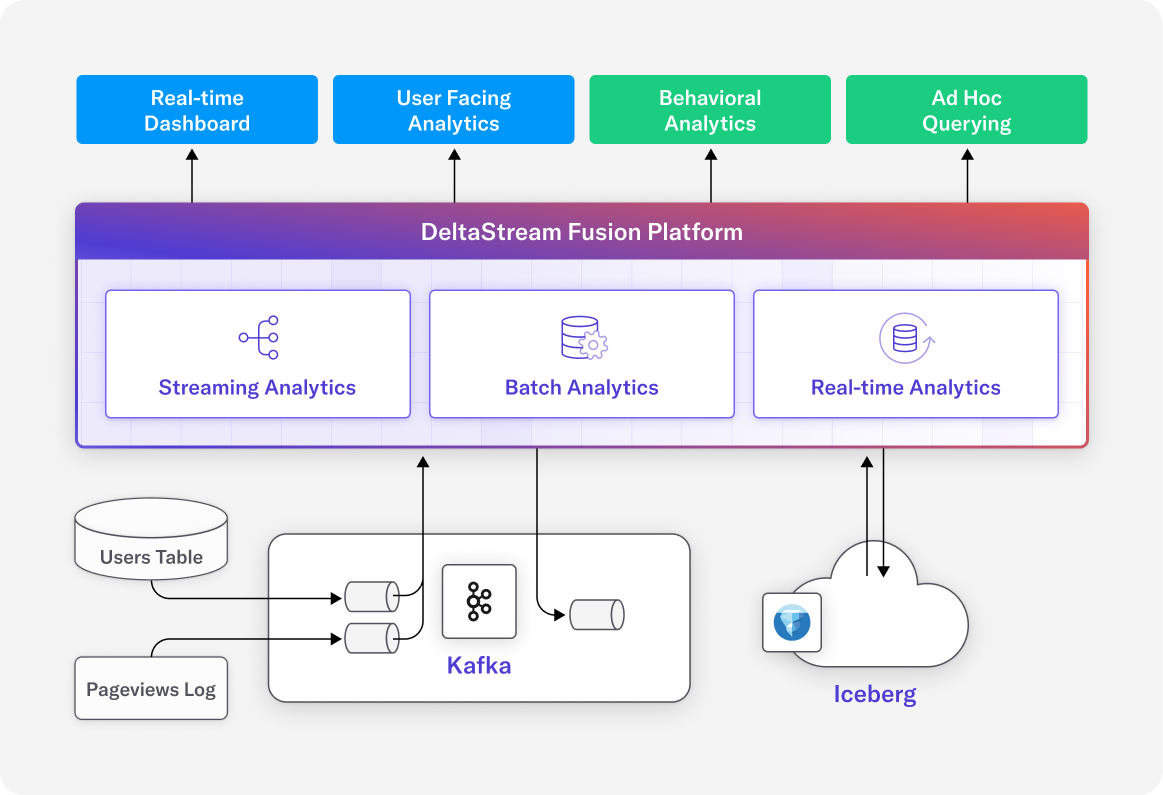
Ingest Once, Stream Forever
Both pipelines began by ingesting the same set of raw JSONL files dropped into an S3 bucket.
Using DeltaStream, the ingestion process was automatic and serverless. New files were picked up as they landed, schemas were versioned and validated, and no custom Spark jobs or manual scripts were needed. In contrast to traditional batch jobs, the system was truly event-driven: ingest once, and the stream keeps flowing. Once data was ingested, we landed it into a Snowflake Bronze table using Snowpipe Streaming.
This stage was identical in both setups and created a consistent starting point. From there, however, the approaches diverged dramatically.
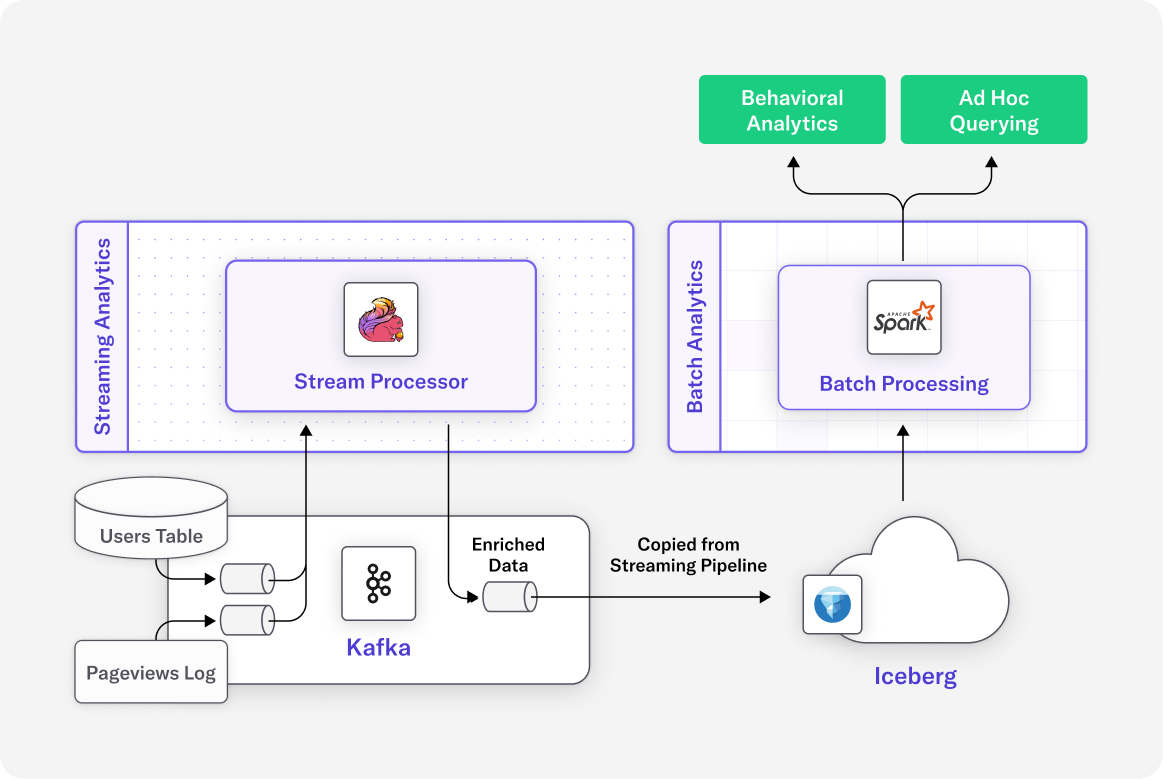
The Snowflake ELT Path: Functional but Expensive
Inside Snowflake, we used two Dynamic Tables to transform and enrich the data. One table cleaned the raw trip data and calculated basic metrics like trip speed. Another joined it with lookup tables to add zone and borough information.
Because Dynamic Tables refresh on a fixed schedule, these transformations ran every 60 seconds, regardless of whether new data had arrived.
Next, we built three additional Dynamic Tables for analytics: one for 15-minute zone aggregates, one for hourly borough stats, and one for daily top zones. While this delivered useful business insights, the cost of constantly running these transformations was substantial.
The cost profile:
- Silver Table Storage: 371 MB
- Warehouse Usage for Dynamic Table Refreshes: $17.72/day
- Snowpipe Streaming: $0.16
Compute was always on, and storage requirements grew with every new version of the Silver and Gold tables.
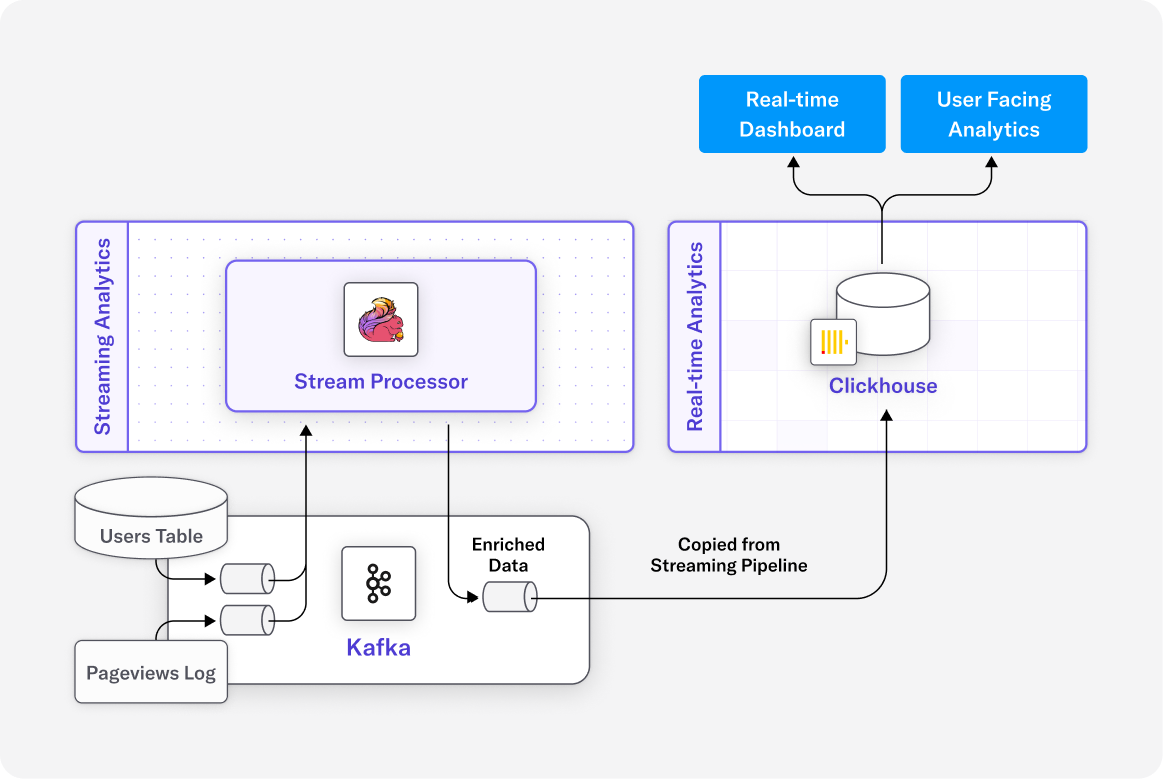
The DeltaStream ETL Path: Leaner, Faster, Cheaper
There were no intermediate Silver tables to maintain. No refresh schedules to manage. As soon as a new file landed in S3, DeltaStream loaded it into Kafka, ran the transformation, and streamed only the final Gold aggregates into Snowflake.
The cost profile:
- Gold Table Storage: 0.64 MB
- Warehouse Usage: $0.17 (initial load only)
- Snowpipe Streaming: $0.40
This approach not only simplified the architecture, but eliminated unnecessary compute and storage costs.
Key Results: 75% Cost Savings!
Over 24 hours, we tracked compute and storage costs across both pipelines:
- Snowflake storage (Silver tables = 371 MB vs Gold tables = .64MB)
- Warehouse usage ($17.72 /day just for refresh vs $.17 for initial Gold table creation)
- Snowpipe Streaming usage (.16 for ELT vs .4 for ETL )
Key Difference: 1-Minute Dynamic Table Refresh vs. Real-Time Updates
The Bottomline: The Snowflake ELT path consumed 4x–10x more compute resources than DeltaStream, a cost savings of more than 75%.
Bonus Benefit: DeltaStream Simplifies Streaming with SQL
Perhaps the most surprising outcome? Simplicity. With DeltaStream, you don’t need to learn Java or wrestle with Flink SDKs. You write SQL, just like in Snowflake. There’s no need to manage watermarks, orchestrate batch windows, or worry about how stream processing frameworks handle state. DeltaStream takes care of all of that—giving you clean, governed, and real-time data with far less operational burden.
You get all the power of streaming ETL—without the learning curve.
The Takeaway: Shift Left and Save Big
This benchmark confirms what many data teams are already realizing: doing everything inside Snowflake might be simple, but it’s not always efficient. With DeltaStream, you can reduce compute and storage costs, shrink latency, and streamline your architecture—all while using familiar SQL.
Shift left. Get fresher data. Cut your Snowflake bill. Stream smarter—with DeltaStream.
Want to see how much we can save you on your Snowflake bill?
Contact us for a complimentary stream assessment with DeltaStream CEO Hojjat Jafarpour.
We’ll evaluate your current architecture, identify quick wins, and deliver a custom action plan to reduce costs, simplify pipelines, and accelerate time to insight.